Share it with your network.
Komprehend has distinguished itself based on its innovation stemming from its rich research centric environment. At Komprehend the mantra is not merely ‘getting the job done’, it is more on the lines of ‘ get the job done in a way that no one has thought about’. In a previous post, we documented a summary of all the research undertaken by Komprehend’s data science team in the year 2018. Our data scientists, however, have not been idle. We have devised an algorithm designed for keyword spotting from a continuous speech sample. Let me break this down for you with a real-world example. Devices like Google Home need an isolated key phrase (OK Google) to jump to life. These key phrases cannot be a part of a sentence or they are not detected. This is the problem our researchers endeavored to solve.
This post is meant to give all of you an overview of the research. You can download the research paper for free by clicking the button at the end of this post. Let us Get Keyword Spotting.
The Use-Cases of Continuous Speech Keyword Spotting
Our researchers aimed to create an algorithm that can detect embedded keywords in a recorded audio sample. The frequency of occurrence of the embedded keywords can be used to discover the theme of the communication (audio sample) under scrutiny. Keyword spotting and frequency of keyword occurrence can also be used to create keyword clouds. Such a word cloud can give its viewer a quick snapshot of the entire snapshot. This research is meant to detect domain-specific keywords. Let me explain this with an example, say two friends discuss the different types of TV models from say Sony. The models can have names like BraviaT380, GloriaT321 or something like that, it is pretty evident that these are not real words and so will not exist in any form of a public data set. So, Automatic Speech Recognition (ASR) systems trained on such public datasets are not an option. A trained CSKS algorithm can efficiently detect such keywords from an audio sample.
The Scope of Our Research and the Challenges we Overcame
The training of a CSKS algorithm is similar to traditional keyword spotting algorithms. Basically classifying small fragments of audio in running speech. Well, the basic idea in simple words is to ignore everything else other than the targeted keywords and also differentiate between the different types of target keywords. Before writing this post I had a long conversation with our researchers. They told me that training a continuous speech keyword spotting algorithm is problematic because of the relatively small amount of labelled keywords to work with. Our researchers devised a one of a kind cocktail combining techniques from the field of few-shot learning, transfer learning, and metric learning to overcome this difficulty.
The research aimed to achieve the following:
- Testing existing Keyword Spotting methodologies for the task of CSKS.
- Proposing a transfer learning based baseline for CSKS by fine tuning weights of a publicly available deep ASR model.
- Introducing changes in training methodology by combining concepts from few-shot learning and metric learning into the transfer learning algorithm to address both the problems which baselines have a) missing keywords and b) false positives
Our researchers created a learning data by recording volunteers as they said the keywords 3 times in unaltered conditions. The aim was to create a system that can successfully spot 20 pre-decided keywords (television models) occurring in an audio recording.
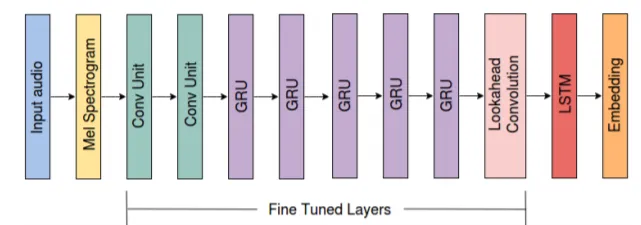
The Deep Learning Architectures Used by Our Researchers
Our researchers used four cutting edge deep learning architectures in order to successfully carry out the research. These were:

- Honk
- DeepSpeech-finetune
- DeepSpeech-finetune-prototypical
- DeepSpeech-finetune-prototypical+metric
To read more about how these models were used in the context of our research click on the button below to download the complete research paper. Download PDF
We hope you liked the article. Please Sign Up for a free Komprehend account to start your AI journey now. You can also check out free demos of Komprehend AI APIs here.
.png)
.png)
.png)