Share it with your network.
There is certainly no doubt that the ultimate future of AI is to reach and surpass human intelligence. But this is a far-fetched feat to achieve. Even the most optimistic ones among us bet that human-level AI (AGI or ASI) to be as far as 10-15 years from now with skeptics even willing to bet that it is going to take centuries, if even possible. Well, this is not what the post is about (you should rather read this post if you are interested in learning about super-intelligence). Here we are going to talk about a more tangible, closer future and discuss about the emerging and potent AI algorithms and techniques which, in our opinion, are going to shape the near future of AI.
AI has started bettering humans in a few selected and specific tasks. For example, beating doctors at diagnosing skin cancer and defeating Go players at the world championship. But the same systems and models will fail in performing the tasks different from the ones they were trained to solve. This is why, in the long run, a generally intelligent system which performs a set of tasks efficiently without the need of reassessment is dubbed as future of AI. But, in the near future of AI, way before the AGI comes up, how will scientists possibly make AI-powered algorithm overcome the problems they face today to come out of labs and become everyday usage objects?
When you look around, AI is winning one castle at a time (read our posts on how AI is outpacing humans, part one and part two). What could possibly go wrong in such a win-win game? Humans are producing more and more data (which is the fodder that AI consumes) with time and our hardware capabilities are getting better as well. After all, data and better computation are the reasons Deep Learning revolution started in 2012 right? The truth is that faster than the growth of data and computation, is the growth of human expectations. Data Scientists would have to think of solutions beyond what exists right now to solve real-world problems. For example, image classification as most people would think is scientifically a solved problem (if we resist the urge to say 100% accuracy or GTFO). We can classify images (let's say into cat images or dog images) matching human capacity using AI. But can this be used for real-world use cases already? Can AI deliver a solution for more practical problems humans are facing? In some cases, yes, but in a lot of cases, we are not there yet.
We'll walk you through the challenges which are the main roadblocks for developing a real-world solution using AI. Let's say you want to classify images of cats and dogs. We'll be using this example throughout the post.

The graphic below summarizes the challenges:

Let us discuss these challenges in detail:
Learning with lesser data:
- The training data most successful Deep Learning algorithms consume requires it to be labeled according to the content/feature it contains. This process is called annotation.
- The algorithms cannot use the naturally found data around you. Annotation of a few hundred (or a few thousand data points) is easy, but our human level image classification algorithm took a million annotated images to learn well.
- So the question is, whether annotating a million images is possible? If not, then how can AI scale with a lesser quantity of annotated data?
Solving diverse real-world problems:
- While datasets are fixed, real-world usage is more diverse (say for example algorithm trained on colored images might fail badly on greyscale images unlike humans).
- While we have improved the Computer Vision algorithms to detect objects to match humans. But as mentioned earlier, these algorithms solve a very specific problem as compared to human intelligence which is far more generic in many senses.
- Our example AI algorithm, which classifies cats and dogs, will not able to identify a rare dog species if not fed with images of that species.
Adjusting the incremental data:
- Another major challenge is incremental data. In our example, if we are trying to recognize cats and dogs we might train our AI for a number of cat and dog images of different species while we first deploy. But on the discovery of a new species altogether, we need to train the algorithm to recognize "Kotpies" along with the previous species.
- While the new species might be more similar to others than we think and can be easily trained to adapt the algorithm on, there are points where this is harder and requires complete re-training and re-assessment.
- The question is can we make the AI at least adaptable to these small changes?
To make AI immediately usable, the idea is to solve the aforementioned challenges by a set of approaches called Effective Learning (please note that it is not an official term, I am just making it up to avoid writing Meta-Learning, Transfer Learning, Few Shot Learning, Adversarial Learning and Multi-Task Learning every time). We, at ParallelDots, are now using these approaches to solve narrow problems with AI, winning small battles while gearing up for more comprehensive AI to conquer bigger wars. Let us introduce you to these techniques one at a time.
Noticeably, most of these techniques of Effective Learning are not something new. They just are seeing a resurgence now. SVM (Support Vector Machines) researchers have been using these techniques for a lot of time. Adversarial Learning, on the other hand, is something came out of Goodfellow’s recent work in GANs and Neural Reasoning is a new set of techniques for which datasets have become available very recently. Let's deep dive into how these techniques are going to help in shaping the future of AI.
Techniques to Revolutionize the Near Future of AI
Transfer Learning
What Is It?
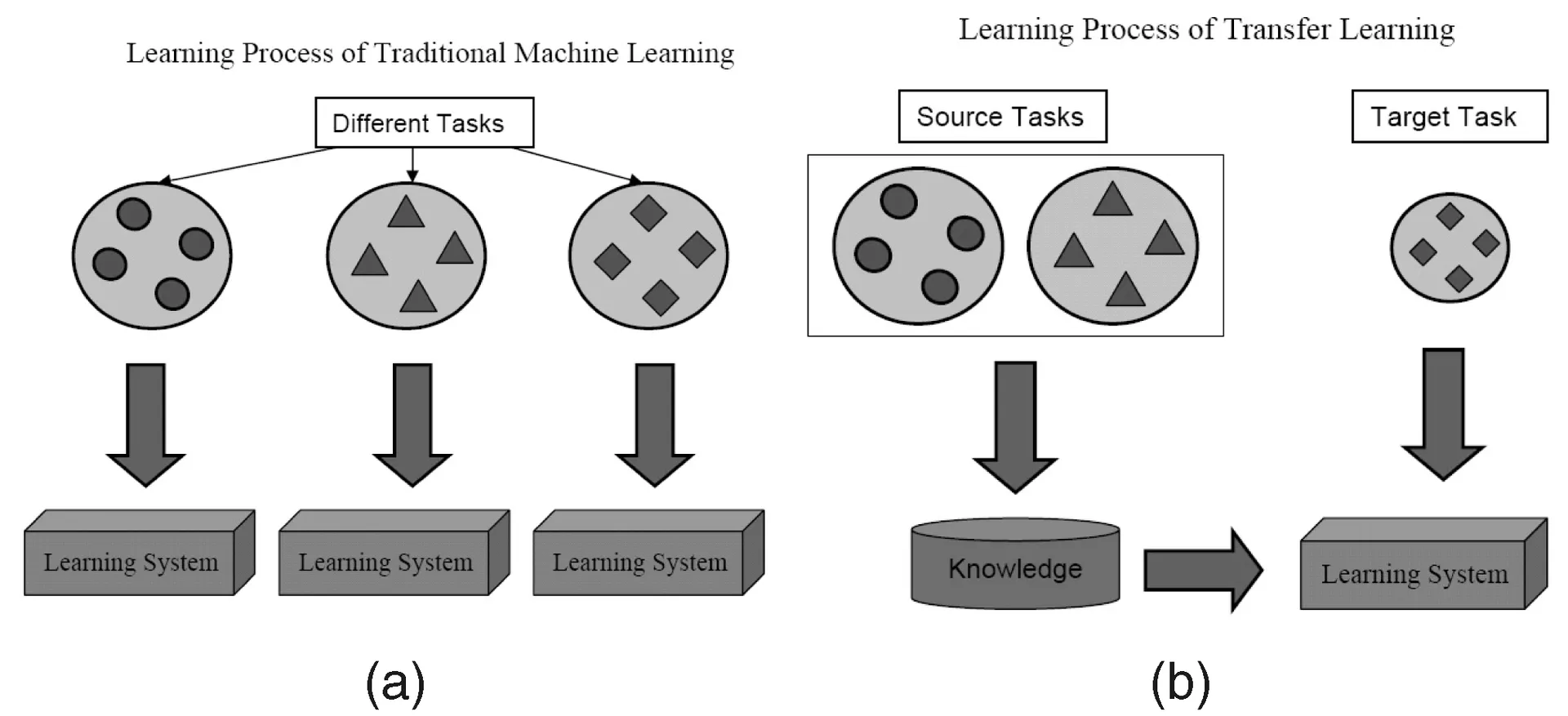
As the name suggests, the learning is transferred from one task to the other within the same algorithm in Transfer Learning. Algorithms trained on one task (source task) with larger dataset can be transferred with or without modification as a part of algorithm trying to learn a different task (target task) on a (relatively) smaller dataset.
Some Examples
Using parameters of an image classification algorithm as a feature extractor in different tasks like object detection is a simple application of Transfer Learning. In contrast, it can also be used to perform to complex tasks. The algorithm Google developed to classify Diabetic Retinopathy better than doctors just sometime back was made using Transfer Learning. Surprisingly, the Diabetic Retinopathy detector was actually a real world image classifier (dog/cat image classifier) Transfer Learning to classify eye scans.
Tell Me More!
You will find Data Scientists calling such transferred parts of neural networks from source to target task as pretrained networks in Deep Learning literature. Fine Tuning is when errors of target task are mildly backpropagated into the pretrained net instead of using the pretrained network unmodified. A good technical introduction to Transfer Learning in Computer Vision can be seen here. This simple concept of Transfer Learning is very important in our set of Effective Learning methodologies.
Multi-Task Learning
What Is It?
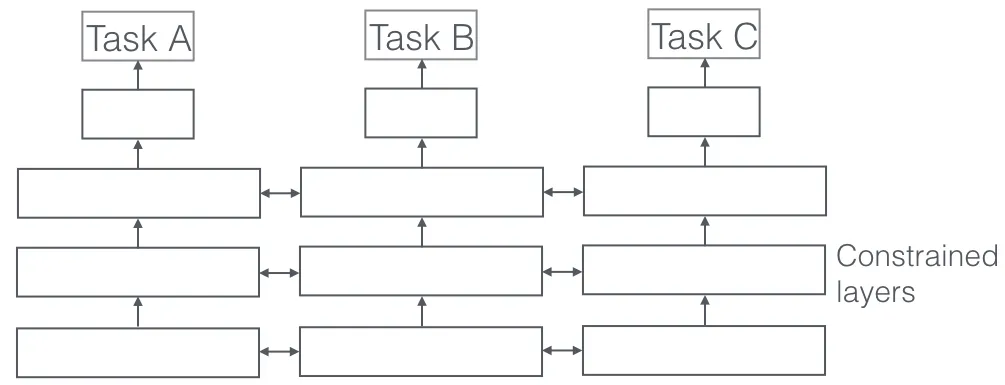
In Multi-Task Learning, multiple learning tasks are solved at the same time, while exploiting commonalities and differences across tasks. It is surprising, but sometimes learning two or more tasks together (also called main task and auxiliary tasks) can make results better for the tasks. Please note that not every pair or triplet or quartet of tasks can be considered auxiliary. But when it works, it is a free increment in accuracy.
Some Examples
For example, at ParallelDots, our Sentiment, Intent and Emotion Detection classifiers were trained as Multi-Task Learning which increased their accuracy compared to if we trained them separately. The best Semantic Role Labelling and POS tagging system in NLP we know is a Multi-Task Learning System, so is one of the best systems for semantic and instance segmentation in Computer Vision. Google came up with multimodal Multi-Task Learners (One model to rule them all) that can learn from both vision and text datasets in the same shot.
Tell Me More!
A very important aspect of Multi-Task Learning that is seen in real-world applications is where training any task to become bulletproof, we need to respect many domains data is coming from (also called domain adaptation). An example in our cat and dog use cases will be an algorithm that can recognize images of different sources (say VGA cameras and HD cameras or even infrared cameras). In such cases an auxiliary loss of domain classification (where the images came in from) can be added to any task and then the machine learns such that the algorithm keeps getting better at the main task(classifying images into cat or dog images), but purposely getting worse at the auxiliary task (this is done by backpropagating the reverse error gradient from the domain classification task). The idea is that the algorithm learns discriminative features for the main task, but forgets features that differentiate domains and this would make it better. Multi-Task Learning and its Domain Adaption cousins are one of the most successful Effective Learning techniques we know of and have a big role to play in shaping the future of AI.
Adversarial Learning
What Is It?
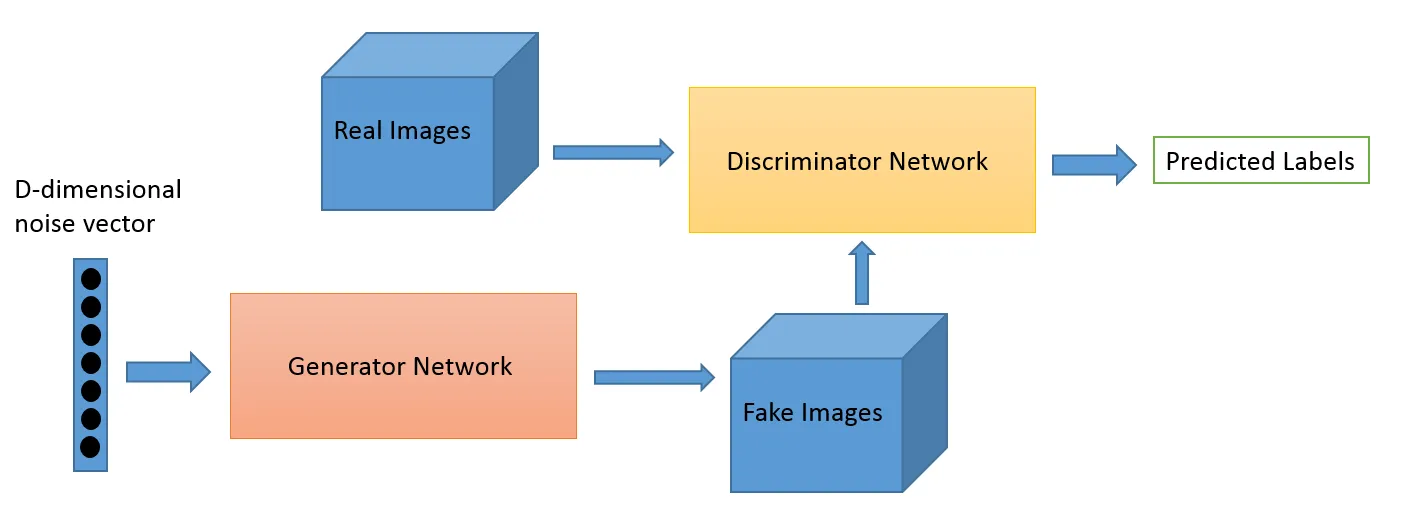
Adversarial Learning as a field evolved from the research work of Ian Goodfellow. While the most popular applications of Adversarial Learning is no doubt Generative Adversarial Networks (GANs) which can be used to generate stunning images, there are multiple other ways this set of techniques. Typically this game theory inspired technique has two algorithms a generator and a disriminator, whose aim is to fool each other while they are training. The generator can be used to generate new novel images as we discussed, but can also can generate representations of any other data to hide details from discriminator. The latter is why this concept is of so much interest to us.
Some Examples
This is a new field and the image generation capacity is probably what most interested people like astronomers focus on. But we believe this will evolve newer use cases too as we tell later.
Tell Me More!
The domain adaptation game can be bettered using the GAN loss. The auxiliary loss here is a GAN system instead of pure domain classification, where a discriminator tries to classify which domain the data came from and a generator component tries to fool it by presenting random noise as data. In our experience, this works better than plain domain adaptation (which is also more erratic to code).
Few Shot Learning
What Is It?
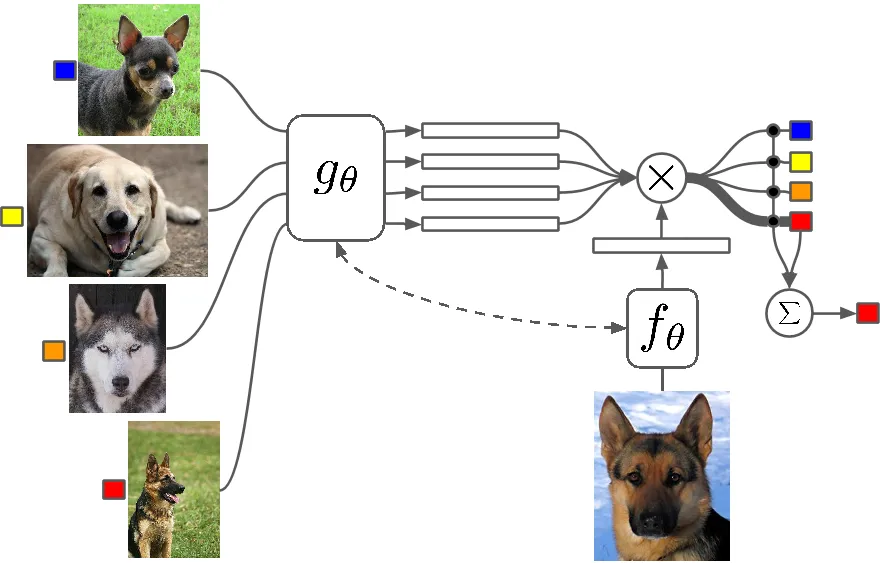
Few Shot Learning is a study of techniques which make Deep Learning (or any Machine Learning algorithm) algorithms learn with less number of examples as compared to what a traditional algorithm would do. One Shot Learning is basically learning with one example of a category, inductively k-shot learning means learning with k examples of each category.
Some Examples?
Few Shot Learning as a field is seeing an influx of papers in all major Deep Learning conferences and there are now specific datasets to benchmark results on, just like MNIST and CIFAR are for normal machine learning. One-shot Learning is seeing a number of applications in certain image classification tasks such as feature detection and representation.
Tell Me More!
There are multiple methods that are used for Few Shot learning, including Transfer Learning, Multi-Task Learning as well as Meta-Learning as all or part of the algorithm. There are other ways like having clever loss function, using dynamic architectures or using optimization hacks. Zero Shot Learning, a class of algorithms which claim to predict answers for categories that the algorithm has not even seen, are basically algorithms that can scale with a new type of data.
Meta-Learning
What Is It?
Meta-Learning is exactly what it sounds like, an algorithm that trains such that, on seeing a dataset, it yields a new machine learning predictor for that particular dataset. The definition is very futuristic if you give it a first glance. You feel “whoa! that’s what a Data Scientist does” and it is automating the “sexiest job of 21st century”, and in some senses, Meta-Learners have started to do that (refer this blog post from Google and this research paper).

Some Examples
Meta-Learning has become a hot topic in Deep Learning recently, with a lot of research papers coming out, most commonly using the technique for hyperparameter and neural network optimization, finding good network architectures, Few-Shot image recognition, and fast reinforcement learning. You can find a more comprehensive article on use cases here.
Tell Me More!
Some people refer to this full automation of deciding both parameters and hyperparameters like network architecture as autoML and you might find people referring to Meta Learning and AutoML as different fields . Despite all the hype around them, the truth is that Meta Learners are still algorithms and pathways to scale Machine Learning with data’s complexity and variety going up.
Most Meta-Learning papers are clever hacks, which according to Wikipedia have following properties:
- The system must include a learning subsystem, which adapts with experience.
- Experience is gained by exploiting meta-knowledge extracted either in a previous learning episode on a single dataset or from different domains or problems.
- Learning bias must be chosen dynamically.
The subsystem basically is a setup that adapts when meta-data of a domain (or an entirely new domain) is introduced to it. This metadata can tell about increasing number of classes, complexity, change in colors and textures and objects (in images), styles, language patterns (natural language) and other similar features. Check out some super cool papers here: Meta-Learning Shared Hierarchies and Meta-Learning Using Temporal Convolutions. You can also build Few Shot or Zero Shot algorithms using Meta-Learning architectures. Meta-Learning is one of the most promising techniques which will help in shaping the future of AI.
Neural Reasoning
What is it?
Neural Reasoning is next big thing in image classification problems. Neural Reasoning is a step above pattern recognition where algorithms are moving beyond the idea of simply identifying and classifying text or images. Neural Reasoning is solving more generic questions in text analytics or visual analytics. For example, the image below represents a set of questions Neural Reasoning can answer from an image.

Tell me more!
This new set of techniques is coming up after the release of Facebook's bAbi dataset or the recent CLEVR dataset . The techniques coming up to decipher relations and not just patterns have immense potential to solve not just Neural Reasoning but also multiple other hard problems including Few Shot learning problems.
Now that we know what are the techniques, let us go back and see how they solve the base problems we started with. The table below gives the snapshot of the capabilities of Effective Learning techniques to tackle the challenges:
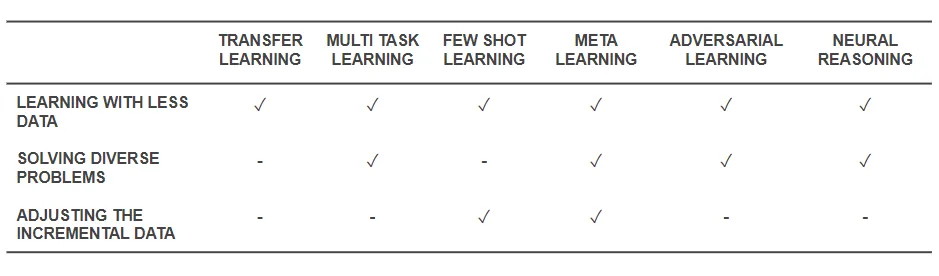
- All the techniques mentioned above help solve training with a lesser amount of data in some way or the other. While Meta-Learning would give architectures that would just mold with data, Transfer Learning is making knowledge from some other domain useful to compensate for fewer data. Few Shot Learning is dedicated to the problem as a scientific discipline. Adversarial Learning can help enhance the datasets.
- Domain Adaptation (a type of Multi-Task Learning), Adversarial Learning and (sometimes) Meta-Learning architectures help solve problems arising from data diversity.
- Meta-Learning and Few Shot Learning help solve problems of incremental data.
- Neural Reasoning algorithms have immense potential to solve real-world problems when incorporated as Meta-Learners or Few Shot Learners.
Please note that these Effective Learning techniques are not new Deep Learning/Machine Learning techniques, but augment the existing techniques as hacks making them more bang for the buck. Hence, you will still see our regular tools such as Convolutional Neural Networks and LSTMs in action, but with the added spices. These Effective Learning techniques which work with fewer data and performs many tasks at a go can help in easier production and commercialization of AI-powered products and services. At ParallelDots, we are recognizing the power of Efficient Learning and incorporating it as one of the main features of our Research philosophy.
.png)
.png)
.png)