Share it with your network.
O reconhecimento de entidades nomeadas (NER), ou extração de entidades, é uma técnica de PNL que localiza e classifica as entidades nomeadas presentes no texto. O reconhecimento de entidades nomeadas classifica as entidades nomeadas em categorias predefinidas, como nomes de pessoas, organizações, locais, quantidades, valores monetários, termos especializados, terminologia do produto e expressões de horários. O reconhecimento de entidades nomeadas faz parte de um campo mais amplo chamado Extração de informações. De acordo com a Wikipedia, a extração de informações é a tarefa de extrair automaticamente informações estruturadas de qualquer tipo de texto, estruturado e/ou não estruturado.
O processamento de linguagem natural observou uma mudança de paradigma na precisão nos últimos anos. Esses grandes avanços podem ser atribuídos em grande parte ao advento do aprendizado profundo. Nos últimos anos, os modelos de redes neurais recorrentes (RNN) tiveram muito sucesso na extração de entidades nomeadas de textos. O NER tem várias aplicações em vários setores da indústria, como indústria de notícias e mídia, mecanismos de pesquisa, recomendações de conteúdo, suporte ao cliente e academia. Nós escrevemos um detalhado postagem no blog em aplicações anteriores do NER.
Neste post, apresentaremos alguns modelos marcantes e trabalhos de pesquisa relacionados ao NER e também discutiremos o modelo que usamos para executar nossa API de extração de entidades. Você pode fazer uma demonstração aqui.
Alguns modelos marcantes para reconhecimento de entidades nomeadas usando aprendizado profundo
Classificador CRF
O reconhecedor de entidades nomeado do Stanford NLP Group é uma implementação de modelos de sequência de campo aleatório condicional (CRF) de cadeia linear.
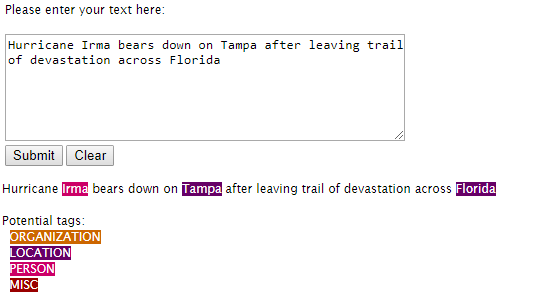
Os modelos de sequência CRF fornecidos aqui não correspondem exatamente a nenhum artigo publicado, mas o artigo correto a ser citado para o modelo e o software é Incorporando informações não locais em sistemas de extração de informações por Gibbs Sampling de Jenny Rose Finkel et al. que foi publicado em 2005. Pode-se baixar seu código, pois é de código aberto, mas estando sob um GPL licença, ela não pode fazer parte de um sistema proprietário.
Abordagem de máxima entropia
A estrutura de entropia máxima estima probabilidades com base no princípio de fazer o mínimo possível de suposições, além das restrições impostas. Essas restrições são derivadas de dados de treinamento, expressando alguma relação entre características e resultados. A distribuição de probabilidade que satisfaz a propriedade acima é aquela com a maior entropia.
Este papel de HL Chieu e HT Ng apresenta uma abordagem de máxima entropia para a tarefa NER, em que o NER não apenas fez uso do contexto local dentro de uma frase, mas também fez uso de outras ocorrências de cada palavra no mesmo documento para extrair recursos úteis (recursos globais). Essas características globais aprimoram o desempenho do NER.
Redes neurais Feedforward para NER
Redes neurais simples de alimentação direta, como isso pode ser um bom modelo de rede neural de linha de base para o NER. Esses modelos são bem simples no sentido de que eles incorporam um conjunto de palavras (3 gramas, 5 gramas) do idioma e tentam prever se a palavra do meio é uma entidade nomeada ou não. 'Pontos paralelos' O primeiro modelo NER foi baseado nessa técnica.
Bilstm-CNNS
Jason Chiu et al. apresentaram um romance arquitetura de rede neural em julho de 2016, que detecta automaticamente características em nível de palavra e de caractere usando uma arquitetura híbrida bidirecional LSTM e CNN, eliminando a necessidade da maior parte da engenharia de recursos.
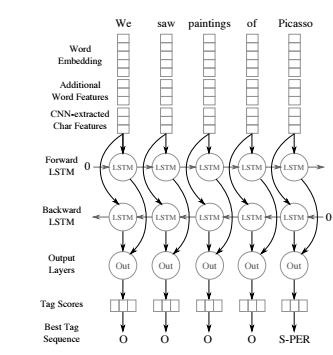
Seu modelo era competitivo no Conjunto de dados ConLL-2003 e supera o desempenho de última geração relatado anteriormente no Conjunto de dados OntoNotes 5.0 por 2,13 pontos na F1. Usando dois léxicos construídos a partir de fontes disponíveis publicamente, eles estabeleceram o novo desempenho de última geração com uma pontuação F1 de 91,62 no ConLL-2003 e 86,28 no OntoNotes, superando os sistemas que empregam engenharia pesada de recursos, léxicos proprietários e informações ricas de vinculação de entidades.
Aprendizagem multitarefa
A transferência e o aprendizado multitarefa tradicionalmente se concentram em um único par fonte-alvo ou em poucas tarefas semelhantes. Kazuma Hashimoto et al. introduziram um modo conjunto de muitas tarefasl no final de 2016, junto com uma estratégia para aumentar sucessivamente sua profundidade para resolver tarefas cada vez mais complexas. As camadas superiores incluem conexões de atalho para previsões de tarefas de nível inferior para refletir hierarquias linguísticas.
Os autores usaram um termo de regularização simples para permitir a otimização de todos os pesos do modelo para melhorar a perda de uma tarefa sem exibir interferência catastrófica das outras tarefas. Seu modelo único de ponta a ponta obteve resultados competitivos ou de última geração em cinco tarefas diferentes, desde tarefas de marcação, análise, relacionamento e vinculação. Modelos similares baseados em MTL também estão sendo usados para treinar o NER com outras tarefas de PNL.
Residual Stack BilsTMS com decodificação tendenciosa
Quan Tran et al. aprimoraram os modelos RNN de última geração para o NER melhorando dois aspectos. A primeira é a introdução de conexões residuais entre o modelo de rede neural recorrente empilhada para resolver o problema de degradação de redes neurais profundas.

A segunda inovação foi um mecanismo de decodificação de viés que permite que o sistema treinado se adapte a objetivos não diferenciáveis e computados externamente, como a medida F baseada em entidades. Seu modelo, Pilha residual BilsTM, melhorou os resultados de última geração para os idiomas espanhol e inglês no conjunto de dados padrão ConLL 2003 Shared Task NER.
Na Paralleldots, usamos LSTMs normais para reconhecimento de entidades nomeadas no último ano, mas criamos um novo modelo recentemente. Agora usamos o Residual Stack BilsTM para treinar nosso API de extração de entidades. Nossa equipe interna de marcação de dados marcou aproximadamente 2 milhões de frases extraídas da Internet com a entidade nomeada na qual treinamos nosso modelo. Por exemplo, a frase “Esta é uma casa que Jack construiu” é anotada com (Jack, Person) e “John e Kim estão indo para Miami” é anotada com (John; Person), (Kim; Person) e (Miami, Place).
Dê uma olhada em nossa demonstração de extração de entidades aqui:

Nos últimos anos, houve uma enxurrada de resultados mostrando que técnicas de aprendizado profundo alcançam resultados de última geração em muitas tarefas de linguagem natural, como modelagem de linguagem, análise e muitas outras. Na Paralleldots, fornecemos várias APIs de PNL. Você pode ver as demonstrações aqui.
.png)
.png)
.png)