Share it with your network.
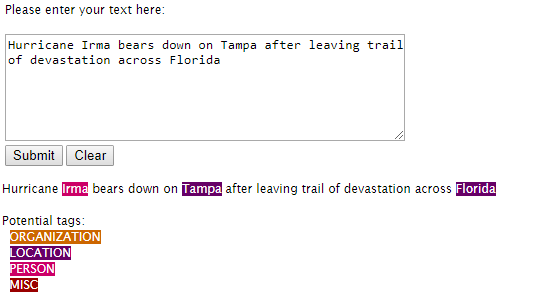
Named Entity Recognition (NER) oder Entitätsextraktion ist eine NLP-Technik, die die im Text vorhandenen benannten Entitäten lokalisiert und klassifiziert. Named Entity Recognition klassifiziert die benannten Entitäten in vordefinierte Kategorien wie Namen von Personen, Organisationen, Standorten, Mengen, Geldwerten, Fachbegriffen, Produktterminologie und Zeitangaben. Named Entity Recognition ist Teil eines umfassenderen Feldes namens Extraktion von Informationen. Laut Wikipedia ist Informationsextraktion die Aufgabe, strukturierte Informationen aus jeder Art von strukturiertem und/oder unstrukturiertem Text automatisch zu extrahieren.
Natural Language Processing hat in den letzten Jahren einen Paradigmenwechsel in Bezug auf die Genauigkeit beobachtet. Diese großen Fortschritte können größtenteils auf das Aufkommen von Deep Learning zurückgeführt werden. In den letzten Jahren waren Modelle von Recurrent Neural Network (RNN) sehr erfolgreich bei der Extraktion benannter Entitäten aus Texten. NER hat verschiedene Anwendungen in verschiedenen Branchen wie der Nachrichten- und Medienbranche, Suchmaschinen, Inhaltsempfehlungen, Kundensupport und Wissenschaft. Wir haben eine ausführliche geschrieben Blogbeitrag zu den bisherigen NER-Anwendungen.
In diesem Beitrag werden wir Sie durch einige Meilensteinmodelle und Forschungsarbeiten zu NER führen und auch das Modell besprechen, mit dem wir unsere Entity Extraction-API ausgeführt haben. Sie können eine Demo machen hier.
Einige Meilensteinmodelle für die Erkennung benannter Entitäten mithilfe von Deep Learning
CRF-Klassifikator
Der Named Entity Recognizer der Stanford NLP Group ist eine Implementierung von CRF-Sequenzmodellen (Conditional Random Field) mit linearer Kette.
Die hier bereitgestellten CRF-Sequenzmodelle entsprechen nicht genau einer veröffentlichten Arbeit, aber das richtige Papier, das für das Modell und die Software zitiert werden muss, ist Einbindung nichtlokaler Informationen in Informationsextraktionssysteme durch Gibbs Sampling von Jenny Rose Finkel et al. das 2005 veröffentlicht wurde. Man kann ihren Code herunterladen, da er Open Source ist, aber unter GPL Lizenz, sie kann nicht Teil eines proprietären Systems sein.
Maximaler Entropie-Ansatz
Der Rahmen für maximale Entropie schätzt Wahrscheinlichkeiten auf der Grundlage des Prinzips, außer den auferlegten Beschränkungen so wenige Annahmen wie möglich zu treffen. Solche Beschränkungen werden aus Trainingsdaten abgeleitet und drücken eine gewisse Beziehung zwischen Merkmalen und Ergebnissen aus. Die Wahrscheinlichkeitsverteilung, die die obige Eigenschaft erfüllt, ist diejenige mit der höchsten Entropie.
Dieses Papier von HL Chieu und HT Ng präsentiert einen Ansatz mit maximaler Entropie für die NER-Aufgabe, bei dem NER nicht nur den lokalen Kontext innerhalb eines Satzes nutzte, sondern auch andere Vorkommen jedes Wortes innerhalb desselben Dokuments nutzte, um nützliche Merkmale (globale Merkmale) zu extrahieren. Solche globalen Merkmale verbessern die Leistung von NER.
Neuronale Feedforward-Netze für NER
Einfache neuronale Feedforward-Netze wie diese kann ein gutes neuronales Basisnetzmodell für NER sein. Diese Modelle sind ziemlich einfach in dem Sinne, dass sie Einbettungen einer Reihe von Wörtern (3 Gramm, 5 Gramm) aus der Sprache übernehmen und versuchen vorherzusagen, ob das Mittelwort eine benannte Entität ist oder nicht. Parallele Punkte“ Das allererste NER-Modell basierte auf dieser Technik.
Bilstm-CNNS
Jason Chiu et al. präsentierten einen Roman Architektur neuronaler Netzwerke im Juli 2016, das automatisch Merkmale auf Wort- und Zeichenebene mithilfe einer hybriden bidirektionalen LSTM- und CNN-Architektur erkennt, sodass die meisten Funktionen nicht mehr benötigt werden.
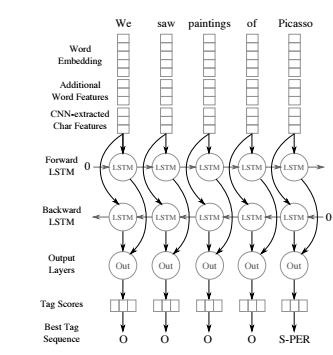
Ihr Modell war wettbewerbsfähig auf dem ConLL-2003-Datensatz und übertrifft die zuvor berichtete Leistung auf dem neuesten Stand der Technik OntoNotes 5.0-Datensatz um 2,13 F1-Punkte. Durch die Verwendung von zwei Lexika, die aus öffentlich zugänglichen Quellen erstellt wurden, erreichten sie den aktuellen Stand der Technik mit einem F1-Score von 91,62 auf ConLL-2003 und 86,28 auf OntoNotes. Damit übertrafen sie Systeme, die viel Feature-Engineering, proprietäre Lexika und umfangreiche Entitätsverknüpfungsinformationen verwenden.
Multitask-Lernen
Transfer und Multitask-Lernen konzentrierten sich traditionell entweder auf ein einziges Quelle-Ziel-Paar oder auf sehr wenige, ähnliche Aufgaben. Kazuma Hashimoto et al. stellten eine vor gemeinsamer Mehraufgabenmodusl Ende 2016, zusammen mit einer Strategie, die Tiefe sukzessive zu erhöhen, um immer komplexere Aufgaben zu lösen. Höhere Ebenen enthalten kurze Verbindungen zu Aufgabenvorhersagen auf niedrigerer Ebene, um sprachlichen Hierarchien Rechnung zu tragen.
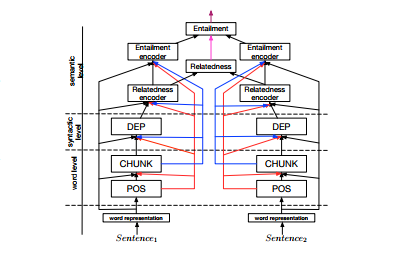
Die Autoren verwendeten einen einfachen Regularisierungsterm, um die Optimierung aller Modellgewichte zu ermöglichen, um den Verlust einer Aufgabe zu verringern, ohne dass die anderen Aufgaben katastrophal beeinträchtigt werden. Ihr einziges durchgängiges Modell lieferte bei fünf verschiedenen Aufgaben — Tagging-, Parsing-, Verwandtschaft- und Entailment-Aufgaben — aktuelle oder wettbewerbsfähige Ergebnisse. Ähnliche MTL-basierte Modelle werden auch verwendet, um NER mit anderen NLP-Aufgaben zu trainieren.
Reststapel BILSTMS mit voreingenommener Decodierung
Quan Tran et al. verbesserten die hochmodernen RNN-Modelle für NER, indem sie zwei Aspekte verbesserten. Der erste ist die Einführung von Restverbindungen zwischen dem Stacked Recurrent Neural Network-Modell, um das Degradationsproblem tiefer neuronaler Netze anzugehen.

Die zweite Innovation war ein Mechanismus zur Decodierung von Verzerrungen, der es dem trainierten System ermöglicht, sich an nicht differenzierbare und extern berechnete Ziele anzupassen, wie z. B. das entitätsbasierte F-Maß. Ihr Modell, Reststapel BILSTM, verbesserte die Ergebnisse auf dem neuesten Stand der Technik sowohl für Spanisch als auch für Englisch im Standard-ConLL 2003 Shared Task NER-Datensatz.
Bei Paralleldots haben wir im letzten Jahr normale LSTMs für Named Entity Recognition verwendet, aber vor Kurzem haben wir ein neues Modell entwickelt. Wir verwenden jetzt Residual Stack BilSTM, um unsere zu trainieren API zur Extraktion von Entitäten. Unser internes Daten-Tagging-Team hat ungefähr 2 Millionen Sätze, die aus dem Internet gecrawlt wurden, mit einer benannten Entität versehen, an der wir unser Modell trainiert haben. Zum Beispiel wird der Satz „Das ist ein Haus, das Jack gebaut hat“ mit (Jack, Person) und „John und Kim gehen nach Miami“ mit (John; Person), (Kim; Person) und (Miami, Place) annotiert.
Schauen Sie sich hier unsere Demo zur Entitätsextraktion an:

In den letzten Jahren gab es eine Flut von Ergebnissen, die zeigen, dass Deep-Learning-Techniken bei vielen Aufgaben in natürlicher Sprache wie Sprachmodellierung, Parsen und vielen anderen hochmoderne Ergebnisse erzielen. Bei Paralleldots bieten wir mehrere NLP-APIs an. Sie können sich die Demos ansehen hier.


.png)