Share it with your network.
Un modelo estadístico no entrenado es como un Ferrari que simplemente no funciona. En otras palabras, simplemente no sirve de mucho. El aprendizaje supervisado se basa en la disponibilidad de datos etiquetados de alta calidad. Los datos etiquetados son el ingrediente que hará rugir a tu Ferrari (modelo estadístico). Para decirlo en términos técnicos, etiquetar los datos de entrenamiento le da al modelo la capacidad de predecir, clasificar y analizar correctamente los datos para generar resultados significativos.
Como regla general, es mejor no desarrollar un modelo si no has descubierto cómo adquirir primero y, lo que es más importante, etiquetar («etiquetar» o «anotar») un conjunto de datos de entrenamiento adecuado.
Etiquetar es un asunto tedioso y lento, ¿verdad? Eche un vistazo a estos ingeniosos métodos que puede utilizar para etiquetar su conjunto de datos sin arruinarse.
Confíe en un modelo de IA Plug-and-Play de terceros

Es mucho más fácil usar modelos previamente entrenados para generar la información que está buscando. Estos modelos de IA listos para usar le ahorran el esfuerzo de crear un modelo funcional, etiquetar y entrenar su conjunto de datos. Todo lo que necesita son datos sin procesar que se puedan conectar a un modelo fiable y bien seleccionado que genere métricas útiles para usted.
El equipo de Komprehend ha desarrollado una gran cantidad de API de este tipo. El uso de estos modelos es muy práctico y está orientado a los resultados. Algunas de las funcionalidades estándar que se abordan en análisis de texto son: análisis de sentimientos, detección de emociones, extractor de palabras clave, similitud semántica y mucho más. Dentro del espacio de la inteligencia visual, Comprehender ha creado un reconocedor de objetos y detección de emociones faciales.
Uso de modelos de aprendizaje no supervisados
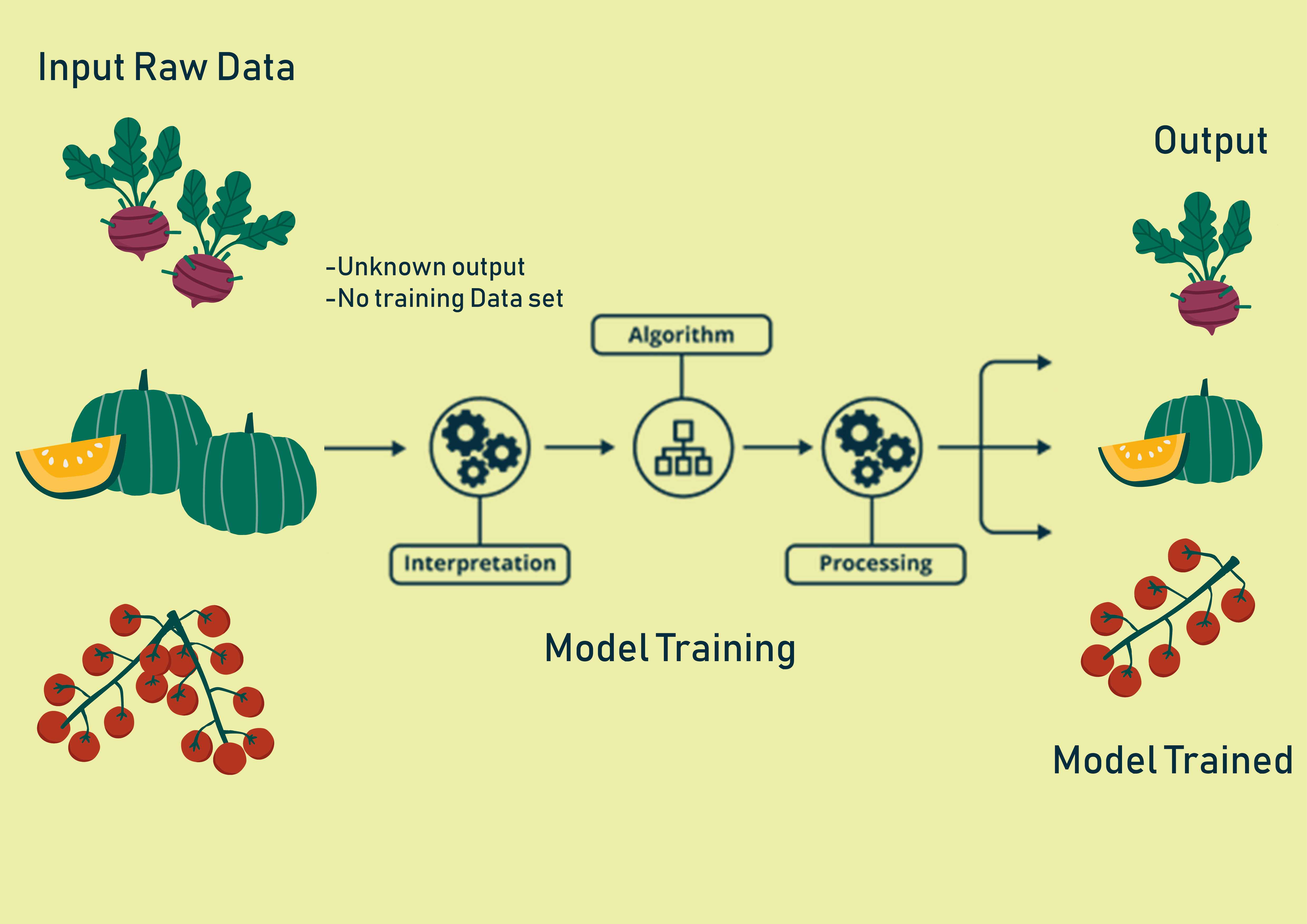
Estos algoritmos de aprendizaje automático pueden aprender de los datos de entrada sin etiquetar. Aprendizaje sin supervisión los algoritmos son un paso hacia el aprendizaje automático. Este enfoque elimina el problema del etiquetado desde la raíz. En lugar de responder a los comentarios, el aprendizaje no supervisado identifica los puntos en común de los datos y reacciona en función de la presencia o ausencia de dichos puntos en común en cada nuevo dato. Esta rama del aprendizaje automático aún está en pañales y aún no se ha desarrollado para producir resultados que superen a los algoritmos de aprendizaje supervisado en términos de precisión y escalabilidad.
El aprendizaje no supervisado también se denomina aprendizaje de tiro cero.
Reestructuración del conjunto de datos existente

El aprendizaje por transferencia es el proceso de reutilizar algunos o todos los datos de entrenamiento, las representaciones de características, la estratificación de los nodos neuronales, los pesos, el método de entrenamiento, la función de pérdida, la tasa de aprendizaje y otras propiedades de un modelo existente. Esta técnica es quizás la estrategia más eficaz para reducir el esfuerzo, el tiempo y el costo asociados con la adquisición de datos etiquetados.
Adquiera datos etiquetados de bajo costo de Open
Recursos web

La World Wide Web está llena de datos sin explotar que esperan ser recopilados si cuentas con las herramientas adecuadas. Decenas de estos fuentes se pueden aprovechar para obtener datos sin costo alguno. Todo lo que realmente necesita es tener acceso a un rastreador de datos ingenioso y puede adquirir un conjunto de datos bien etiquetado para ponerse manos a la obra. Sin embargo, tenga cuidado de no violar ningún derecho de propiedad de los datos mientras lo hace. Y recuerde actualizar los datos adquiridos para adaptarlos a sus necesidades.
Utilice proveedores de servicios que puedan etiquetar sus datos por usted

Si los recursos humanos son un problema para su organización, hay proveedores de servicios que pueden hacer el trabajo duro y proporcionarle datos bien etiquetados. Estos proveedores de servicios suelen resultar económicos y confiables. En algunos casos, subcontratar la tarea de etiquetado de datos a proveedores de servicios comerciales resulta mucho más escalable que llevar a cabo la tarea internamente. Algunos de los actores en este ámbito son Scale, DataPure y LabelBox.
Incruste tareas de etiquetado en aplicaciones en línea

Captcha los desafíos son habituales en Internet. Una técnica ingeniosa para adquirir datos etiquetados puede consistir en aprovechar estos desafíos incorporando los datos de entrenamiento sobre ellos. Esta técnica resulta muy eficaz para entrenar modelos de reconocimiento de texto e imágenes. Otra técnica popular es integrar los datos de entrenamiento en aplicaciones de teléfonos inteligentes que incentivan a su base de usuarios a identificar, clasificar o comentar de otro modo el texto o la imagen presentados.
Esperamos que os haya gustado el artículo. Por favor Inscríbase para obtener una cuenta Komprehend gratuita para comenzar su viaje con la IA ahora. También puedes echar un vistazo a las demostraciones gratuitas de las API de Komprehend AI aquí.


.png)