Share it with your network.
Ein untrainiertes statistisches Modell ist wie ein Ferrari, der einfach nicht läuft. Mit anderen Worten, es nützt einfach nicht viel. Überwachtes Lernen basiert auf der Verfügbarkeit qualitativ hochwertiger, beschrifteter Daten. Markierte Daten sind die Zutat, die Ihren Ferrari (statistisches Modell) zum Brüllen bringt. Technisch ausgedrückt: Die Kennzeichnung Ihrer Trainingsdaten gibt Ihrem Modell die Möglichkeit, Daten korrekt vorherzusagen, zu klassifizieren und auf andere Weise zu analysieren, um aussagekräftige Ergebnisse zu generieren.
Faustregel: Es ist am besten, kein Modell zu entwickeln, wenn Sie nicht herausgefunden haben, wie Sie zuerst einen geeigneten Trainingsdatensatz erfassen und dann, was noch wichtiger ist, kennzeichnen („taggen“ oder „annotieren“).
Etikettieren ist eine mühsame und zeitaufwändige Angelegenheit, nicht wahr? Schauen Sie sich diese genialen Methoden an, mit denen Sie Ihren Datensatz etikettieren lassen können, ohne das Budget zu sprengen.
Verlassen Sie sich auf ein Plug-and-Play-KI-Modell eines Drittanbieters

Es ist viel einfacher, vortrainierte Modelle zu verwenden, um die gewünschten Erkenntnisse zu generieren. Diese Plug-and-Play-KI-Modelle ersparen Ihnen den Aufwand, ein Funktionsmodell zu erstellen, Ihren Datensatz zu kennzeichnen und zu trainieren. Sie benötigen lediglich Rohdaten, die in ein gut kuratiertes und zuverlässiges Modell integriert werden können, das nützliche Metriken für Sie generiert.
Eine ganze Reihe solcher APIs wurde vom Komprehend-Team entwickelt. Die Verwendung dieser Modelle ist sehr praktisch und ergebnisorientiert. Einige der Standardfunktionen, die in diesem Dokument behandelt werden Textanalyse sind - Stimmungsanalyse, Emotionserkennung, Keyword-Extraktor, semantische Ähnlichkeit und vieles mehr. Im Bereich der visuellen Intelligenz Verstehen hat eine Objekterkennung und Gesichtsemotionserkennung entwickelt.
Verwendung von Modellen des unbeaufsichtigten Lernens
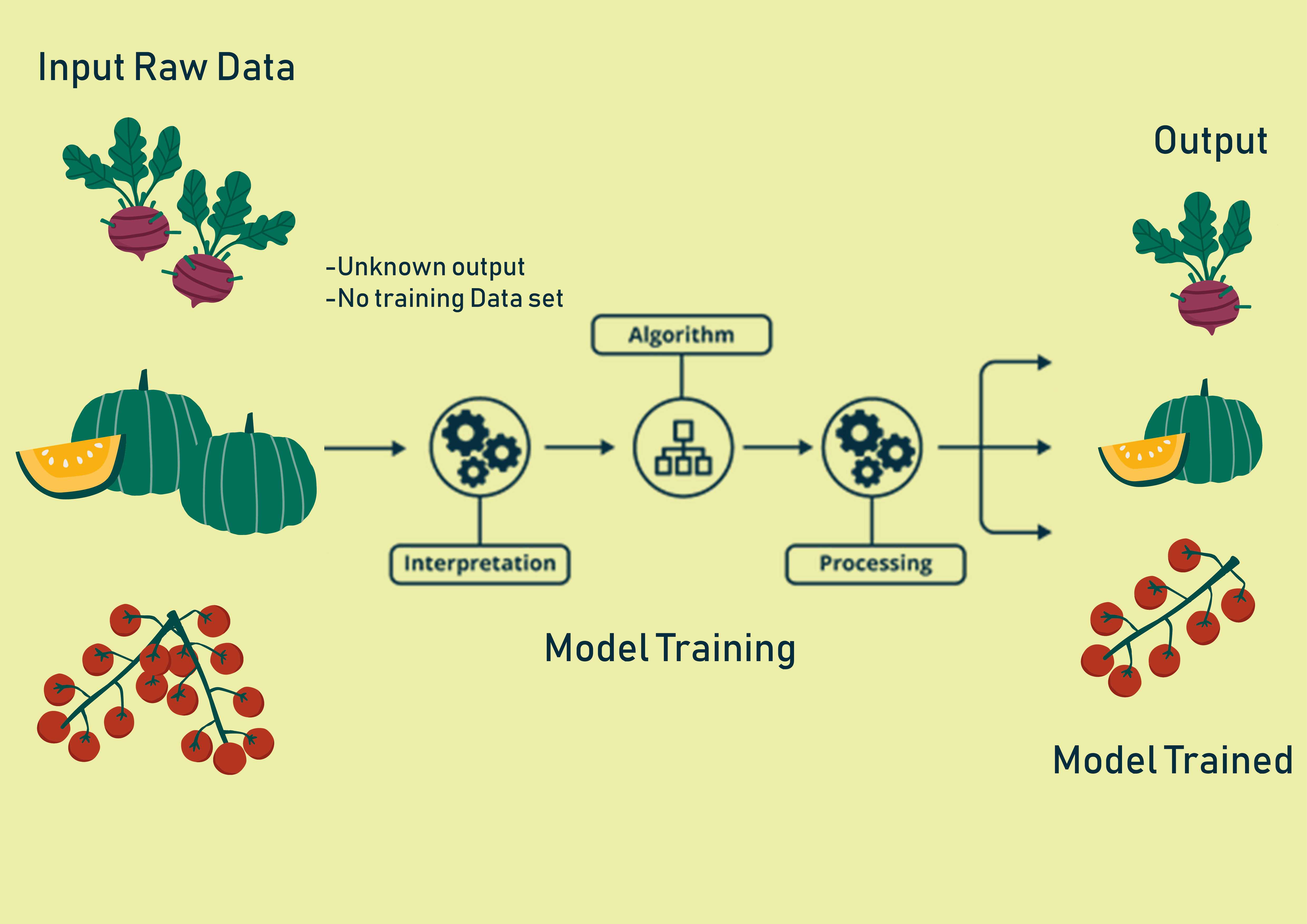
Diese Algorithmen für maschinelles Lernen können aus unbeschrifteten Eingabedaten lernen. Unbeaufsichtigtes Lernen Algorithmen sind ein Schritt in Richtung automatisiertes maschinelles Lernen. Dieser Ansatz beseitigt das Problem der Kennzeichnung von Anfang an. Anstatt auf Feedback zu reagieren, identifiziert unbeaufsichtigtes Lernen Gemeinsamkeiten in den Daten und reagiert auf der Grundlage des Vorhandenseins oder Nichtvorhandenseins solcher Gemeinsamkeiten in jedem neuen Datenelement. Dieser Zweig des maschinellen Lernens steckt noch in den Kinderschuhen und muss erst noch entwickelt werden, um Ergebnisse zu erzielen, die die Algorithmen für überwachtes Lernen in Bezug auf Genauigkeit und Skalierbarkeit übertreffen.
Unbeaufsichtigtes Lernen wird auch als Zero-Shot Learning bezeichnet.
Restrukturierung des bestehenden Datensatzes

Transferlernen ist der Prozess der Wiederverwendung einiger oder aller Trainingsdaten, Merkmalsdarstellungen, neuronaler Knotenschichten, Gewichte, Trainingsmethode, Verlustfunktion, Lernrate und anderer Eigenschaften eines vorhandenen Modells. Diese Technik ist vielleicht die effektivste Strategie, um den Aufwand, die Zeit und die Kosten zu senken, die mit der Erfassung beschrifteter Daten verbunden sind.
Erwerben Sie kostengünstige etikettierte Daten von Open
Web-Ressourcen

Das World Wide Web ist voller ungenutzter Daten, die nur darauf warten, gesammelt zu werden, vorausgesetzt, Sie haben die richtigen Tools. Dutzende davon Quellen können kostenlos auf Daten zugegriffen werden. Alles, was Sie wirklich benötigen, ist der Zugriff auf einen raffinierten Datencrawler, und Sie können einen gut beschrifteten Datensatz abrufen, um die Dinge in Gang zu bringen. Achten Sie jedoch darauf, keine Dateneigentumsrechte zu verletzen, wenn Sie gerade dabei sind. Und denken Sie daran, die erfassten Daten an Ihre Bedürfnisse anzupassen.
Verwenden Sie Dienstleister, die Ihre Daten für Sie kennzeichnen können

Wenn die Personalabteilung ein Problem für Ihr Unternehmen ist, gibt es Dienstleister, die die grundlegende Arbeit erledigen und Ihnen gut beschriftete Daten zur Verfügung stellen können. Diese Dienstleister erweisen sich oft als kostengünstig und zuverlässig. In einigen Fällen erweist sich die Auslagerung der Datenkennzeichnung an kommerzielle Dienstleister als wesentlich skalierbarer als die interne Durchführung der Aufgabe. Einige der Akteure in diesem Bereich sind Scale, DataPure und LabelBox.
Etikettierungsaufgaben in Online-Anwendungen einbetten

Captcha Herausforderungen sind im Internet alltäglich. Eine geniale Technik zur Erfassung markierter Daten kann darin bestehen, diese Herausforderungen zu nutzen, indem Sie Ihre Trainingsdaten über sie einbetten. Diese Technik erweist sich als sehr effektiv für das Training von Text- und Bilderkennungsmodellen. Eine weitere beliebte Technik ist das Einbetten Ihrer Trainingsdaten in Smartphone-Anwendungen, wodurch die Nutzerbasis dazu angeregt wird, präsentierten Text oder Bild zu identifizieren, zu klassifizieren oder auf andere Weise zu kommentieren.
Wir hoffen, dir hat der Artikel gefallen. Bitte Melde dich an für ein kostenloses Komprehend-Konto, um jetzt Ihre KI-Reise zu beginnen. Sie können sich auch kostenlose Demos der Komprehend KI-APIs ansehen hier.


.png)