Share it with your network.
2020 [y la primera mitad de 2021] fue un cisne negro. Las familias, las sociedades y las empresas tuvieron que enfrentarse a cosas que no podían haber concebido. En este artículo, trataré de destacar cómo el equipo de inteligencia artificial de ParallelDots se ha ido adaptando en este período y creando soluciones para la próxima generación de nuestras soluciones de IA para el sector minorista.
ParallelDots pasó al modo de trabajo remoto completo en febrero de 2020 y, desde entonces, el equipo no se ha reunido físicamente durante un día. Antes de eso, siempre habíamos sido una unidad muy unida y, por lo tanto, las primeras semanas las dedicamos por completo a crear una cultura de trabajo remoto. Teníamos que pensar en una mejor comunicación y en una estructura de propiedad muy diferente. Teniendo en cuenta que la empresa también estaba atravesando una crisis empresarial, estas semanas fueron difíciles. Personalmente, estoy orgulloso de la forma en que nuestro equipo manejó la presión y no solo se adaptó, sino que evolucionó hasta convertirse en la máquina batidora de mejor tecnología que siempre ha sido. Solo unas semanas de ajustes y volvimos a ser geniales.
Desafíos para el equipo de IA [alrededor de marzo de 2020]
[Puede que el «por qué» de los diferentes algoritmos y sistemas de IA que estamos creando te parezca aburrido, lo sé porque lo habría hecho 😉, en caso de que solo te interese el «cómo», o toda la nueva sección de tecnologías y algoritmos geniales, pasa a la sección «Nuevos sistemas y algoritmos»]
La función del equipo de IA de ParallelDots consiste en resolver diferentes problemas que obstaculizan nuestra infraestructura de entrenamiento e implementación de IA en ParallelDots. Puede dividir estos desafíos en: A. Obstáculos en el entrenamiento y la precisión de la IA [o obstáculos en la investigación] y B. Obstáculos en el despliegue y la inferencia [o cuellos de botella en el MLOPS, como los llamamos nosotros]. A principios de 2020, cuando nuestra tecnología de inteligencia artificial ya procesaba más de un millón de imágenes al mes, algunos de los desafíos que teníamos que resolver para ampliarla eran:
- Implementación de una infraestructura de inferencia que pueda ampliarse automáticamente en caso de que haya demasiadas imágenes comerciales que procesar para preservar nuestros SLA y, al mismo tiempo, asegurarnos de que la implementación se reduzca para cargas de trabajo pequeñas. Las GPU son máquinas costosas y tener una infraestructura estática [o de desarrollo manual o lista para usar] es la cuerda floja entre cumplir los SLA y evitar los altos costos.
- Hacer que nuestros algoritmos de visión artificial para minoristas se ejecuten en teléfonos. Siempre habíamos pensado en un nuevo producto en el que la IA avanzada pudiera usarse en el teléfono de pequeñas tiendas minoristas con una conexión a Internet lenta para la facturación, el GRN y la gestión del inventario. No solo eso, sino que algunos de nuestros posibles clientes de Shelfwatch querían sistemas que pudieran usarse en las tiendas para obtener conclusiones rápidas sin tener que esperar a que las imágenes se cargaran y procesaran. Sabíamos que si podíamos hacer que nuestros algoritmos de inteligencia artificial para minoristas funcionaran en teléfonos, nos ayudaría a crear el segundo producto de nuestros sueños, pero también ayudaría a que nuestro producto actual atraiga nuevos clientes. Los dos desafíos anteriores son desafíos de MLOPS, como los llamamos nosotros.
- Detección de variantes de tamaño de productos en imágenes. Otro desafío fue detectar las variaciones en el nivel de tamaño de un producto en las imágenes de venta minorista. Por ejemplo, supongamos que tienes una imagen para una estantería llena de patatas fritas y tienes que detectar los recuentos no solo del masala mágico de Lay usando IA, sino también dividirlo entre paquetes de 10 INR, 20 INR y 30 INR del masala mágico de Lay en tu análisis. Para las personas que no han trabajado en visión artificial, este podría parecer el siguiente problema obvio y sencillo de resolver, dado que la IA puede detectar los productos en las estanterías y clasificarlos como marcas con una precisión muy alta. Pero ya conocéis el famoso XKCD #1425 [Siempre hay un XKCD adecuado para todo]. XKCD relevante
- Verificación de partes de materiales de punto de venta. Otra parte del análisis de las imágenes de los estantes, además de detectar e identificar los productos en los estantes, es verificar la presencia de varios materiales de punto de venta en los estantes. Estos materiales de punto de venta son cosas que se suelen ver en una tienda minorista o kirana cercana, como listones para estanterías, recortes, pósters, góndolas y estanterías para demostraciones. Hemos utilizado la función Deep Keypoint Matching para este tipo de partidas durante mucho tiempo y antes funcionaba bien. Sin embargo, con el tiempo, los clientes nos pedían no solo que verificáramos el POSM en las imágenes de las estanterías, sino que también señaláramos las piezas que faltaban y que un comerciante podría haber omitido en un POSM. Por ejemplo, es posible que un comerciante no haya colocado un póster en una estantería de demostración o que se lo haya quitado de la tienda debido a algún accidente. Para hacerlo con precisión y a un nivel adecuado para la clasificación de imágenes, necesitábamos un algoritmo que funcionara en todas partes sin necesidad de formación, ya que los POSM cambian en cuestión de semanas o meses.
- Entrenamiento de detectores de productos de estantería más precisos. Retail Shelf Computer Vision ha pasado a la tecnología de tener un detector de objetos de estantería genérico [extraer cualquier objeto de estantería sin clasificarlo] en el primer paso y, luego, clasificar los productos y luego extraerlos en el segundo paso para evitar los problemas que crean los detectores y clasificadores en un solo paso [enorme asimetría de los productos en las estanterías que crea malos resultados de clasificación, capacitación con muchos datos por proyecto y sin beneficio incremental de la IA, que mejora con proyectos anteriores, etc.]. Ya teníamos un sistema de este tipo compuesto por un detector de objetos de estantería genérico y un clasificador de última generación en una segunda etapa en 2019, pero las formas de las cajas de salida del detector de objetos de estantería podrían haber sido mejores.
- Utilizar el entrenamiento anterior de IA y las correcciones de errores para entrenar mejor y más rápido a los clasificadores. Formamos muchos clasificadores [modelos que clasifican los objetos de estantería extraídos mediante el algoritmo del paso 1 en una de las marcas de productos que necesitamos]. ¿Hay alguna forma de utilizar todos los datos de entrenamiento que recopilamos, incluidos los errores de los clasificadores anteriores, para crear un algoritmo que pueda ayudar a entrenar nuevos clasificadores de forma rápida y precisa? Es una pregunta que siempre se plantea. Los cuatro problemas de investigación [3-6] que habéis descubierto reflejaban los nuevos requisitos de nuestro producto Shelfwatch [3,4] y la mejora del sistema existente [5,6]. Ahora también había una serie de problemas de investigación en nuestra pila de API de PNL.
- Una API de análisis de sentimientos más genérica. La API de análisis de sentimientos que teníamos en línea estaba capacitada para tuits anotados internamente y, a pesar de tener una gran precisión, podía fallar en temas más específicos de un dominio, como artículos políticos o financieros. A diferencia de los tuits, las personas que no tienen experiencia en el dominio de un conjunto de datos tienen dificultades para anotar artículos de diferentes dominios. El uso de una gran cantidad de datos sin anotar para entrenar clasificadores que pudieran funcionar en todos los dominios ha sido un desafío que siempre ha existido.
- Una nueva API de opiniones segmentadas. El análisis de sentimientos basado en aspectos existe desde hace algún tiempo. Finalmente, teníamos un conjunto de datos anotado interno para dicho análisis, pero nuestro objetivo era algo más específico. Queríamos crear una API en la que la frase «La manzana no estaba sabrosa, pero la naranja estaba muy rica». Daría un resultado negativo cuando se analizara para «manzana» o positivo cuando se analizara para ver si había naranja. Por lo tanto, nuestro objetivo era crear un algoritmo de análisis de sentimientos basado en aspectos de última generación.
Ahora que te he aburrido con los detalles de los desafíos que intentábamos resolver, pasemos a la parte interesante. Nuestras nuevas plataformas y algoritmos MLOPS.
Nuevos sistemas y algoritmos
Permítanme presentarles a mis nuevos amigos algunos increíbles sistemas tecnológicos y algoritmos de inteligencia artificial que hemos desarrollado e implementado durante la última vez para abordar los cuellos de botella.
IA de reconocimiento de productos móviles o IA de reconocimiento de estanterías móviles
Introducción a ParallelDots Oogashop — Enlace
Hemos creado e implementado no uno, sino dos tipos diferentes de algoritmos de IA en dispositivos móviles. Es posible que hayas visto nuestras publicaciones extremadamente virales de hace unos días, en las que hacíamos una demostración de la facturación de teléfonos móviles y hablábamos sobre las auditorías de estantería fuera de línea.
Este es el enlace a la función de reconocimiento de imágenes en el dispositivo (ODIN) de ShelfWatch: Enlace
(Artículo)
Básicamente, estos modelos de IA son versiones reducidas de los modelos que implementamos en la nube. Con cierta pérdida de precisión, estos modelos ahora son lo suficientemente pequeños como para funcionar en la GPU de un teléfono [que es mucho más pequeña que una GPU de servidor]. Los nuevos marcos de implementación móvil de Tensorflow son los que utilizamos para implementar estos modelos en nuestras aplicaciones OOGASHOP y ShelfWatch, respectivamente.
Segmentación compacta de estanterías minoristas (en papel) para la implementación móvil — Enlace
Pratyush Kumar, Muktabh Mayani Srivastava
Escalamiento automático de la inferencia de IA en la nube
Cuando las tiendas abren alrededor de las 11 de la mañana [a las 11 de la mañana para diferentes zonas horarias, es decir, en cualquier parte del mundo donde nuestros clientes tengan su fuerza de ventas o comerciantes], nuestros servidores se enfrentan a una enorme cantidad de comerciantes que suben fotos a nuestra nube para procesarlas e informarles sobre su puntuación de ejecución minorista. Y después, pasadas las 11 de la noche, cuando las tiendas minoristas cierran, apenas tenemos suficiente carga de trabajo de inferencia de inteligencia artificial. Si bien muchos proveedores han introducido el escalado automático similar a Lambda, queríamos una técnica de escalado automático independiente de la nube para nuestra infraestructura de inferencia de inteligencia artificial. Cuando hay más imágenes en nuestra cola de procesamiento, necesitamos más GPU para procesarlas; de lo contrario, solo una o quizás ninguna. Para ello, toda la capa de inferencia de la IA se trasladó a una arquitectura basada en Docker, Kubernetes y KEDA, donde se puede generar una cantidad arbitraria de nuevas GPU en función de la carga de trabajo. Ya no es una cuerda floja que consiste en tratar de gestionar el SLA de la empresa y ahorrar dinero en las costosas máquinas con GPU.
Mejora de los algoritmos de detección de objetos en estantería
(Documento) Aprendizaje de mapas gaussianos para la detección de objetos densos — Enlace
Sonaal Kant
Habíamos estado usando RCNN simples de Faster entrenados anteriormente para la extracción de objetos de estantería: Documento de referencia simple sobre la detección de objetos . Funcionó bien en muchos casos de uso, pero necesitábamos enfoques más avanzados. En 2020, nuestro equipo descubrió un nuevo método para usar mapas gaussianos para obtener resultados de última generación. Este trabajo [publicado más tarde] en BMVC, una de las principales conferencias sobre visión artificial Sitio web de BMVC ] nos ayudó a obtener no solo resultados satisfactorios sino también los mejores posibles en la detección de objetos en una estantería.
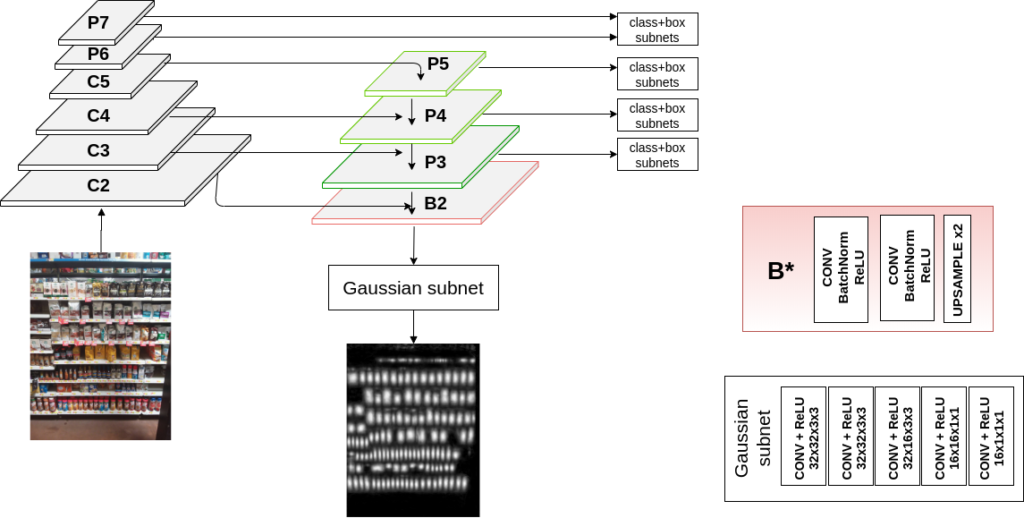
Básicamente, el truco consiste en utilizar el entrenamiento con mapas gaussianos como una pérdida auxiliar para la detección de objetos. Esto hace que las cajas para diferentes productos sean mucho más precisas.
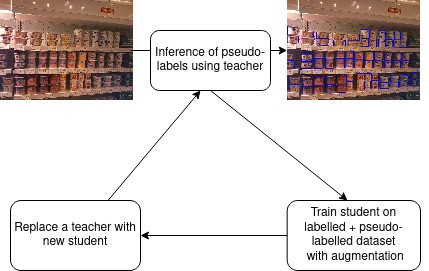
Otra cuestión que hemos estado intentando abordar durante mucho tiempo en términos de detección de objetos en estanterías ha sido: ahora que la necesidad de reconocer los productos se ha trasladado a una tarea posterior y la tarea consiste en dibujar cajas sobre todos los productos posibles, ¿hay alguna forma de utilizar los ruidos y las distorsiones contenidos en un enorme conjunto de datos sin anotaciones para detectar mejor los objetos en las estanterías? En un trabajo reciente, [mencionado en Taller de RetailVision en CVPR 2021 Taller sobre Retail Vision ], utilizamos nuestro enorme repositorio de imágenes de estanterías sin anotaciones para mejorar la precisión de la tarea de detección de objetos en estanterías.
(Papel) Aprendizaje semisupervisado para la detección de objetos densos en tiendas minoristas — Enlace
Jaydeep Chauhan, Srikrishna Varadarajan, Muktabh Mayank Srivastava
La formación de estudiantes basada en psuedolabel es un truco que hemos utilizado en varios campos, no para la detección de objetos en estanterías. Si bien otras técnicas de autoaprendizaje requieren cargar grandes lotes en las GPU, lo que dificulta que una empresa como ParallelDots con hardware limitado como ParallelDots las pruebe, las seudolabiquetas son lo que hemos adaptado como nuestro truco para hacer el autoaprendizaje con una sola GPU.
Mejora de la precisión de la clasificación
Hemos utilizado varios trucos en el pasado para entrenar clasificadores precisos con gran precisión.
Bolsa de trucos (de papel) para la clasificación de imágenes de productos minoristas — Enlace, que ilustra cómo entrenamos a los clasificadores con gran precisión.
Muktabh Mayani Srivastava
Todas las cajas que el detector de objetos de estantería extrae de una imagen de estantería pasan por este clasificador para deducir la marca del producto.

Sin embargo, con los catálogos de las tiendas que cambian con frecuencia, nuestro clasificador de productos debe evolucionar para hacer las cosas de manera un poco diferente. Entrenar un clasificador requiere muchos recursos, ya que los productos se añaden o eliminan rápidamente de los catálogos de las tiendas. Necesitamos un clasificador que pueda entrenarse rápidamente y que sea más preciso o, al menos, tan preciso como los métodos que implican afinar toda la estructura básica. Esto es como tener lo mejor de los dos mundos y puntuar, y eso es lo que se ha demostrado que las técnicas de autoaprendizaje funcionan en el aprendizaje profundo. Hemos estado intentando utilizar los conceptos del autoaprendizaje para crear clasificadores que puedan entrenarse con mucha ligereza.
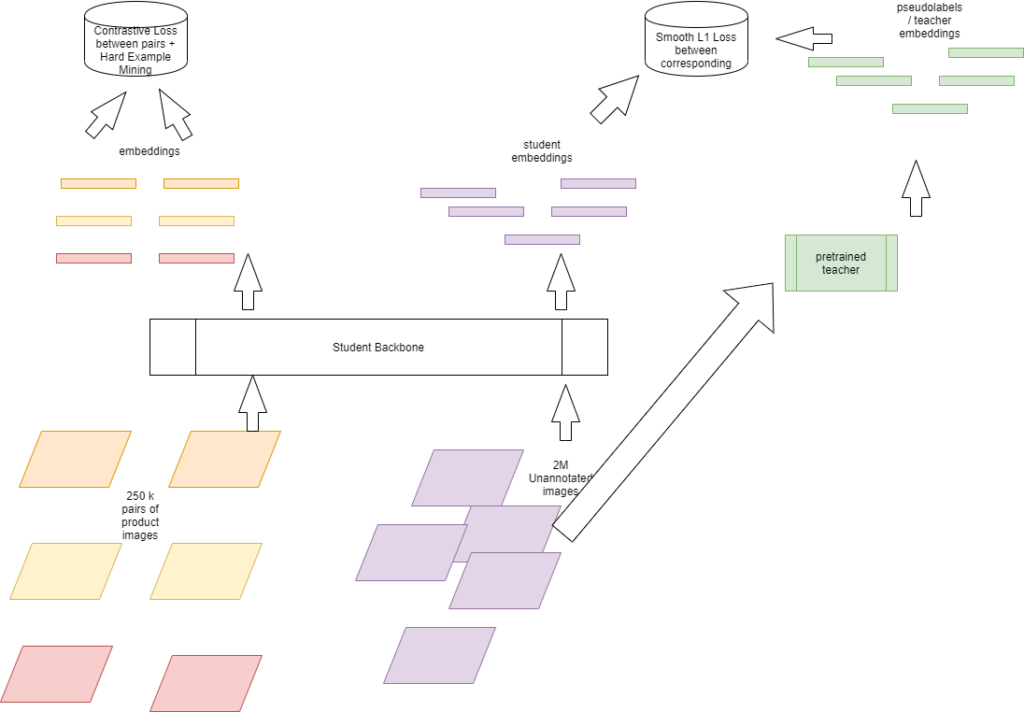
(Papel) Uso del aprendizaje contrastivo y las seudomarcadoras para aprender las representaciones para la clasificación de imágenes de productos minoristas — Enlace
Muktabh Mayani Srivastava
El truco que utilizamos aquí es emplear el enorme repositorio de imágenes de productos minoristas que tenemos [tanto con anotaciones como sin anotaciones] para capacitar a un estudiante de representación, cuyo resultado puede enviarse a un clasificador de aprendizaje automático simple para que lo capacite. Estas representaciones de características aprendidas funcionan bastante bien. Qué guay es entrenar a un pequeño clasificador de regresión logística para clasificar imágenes de tiendas minoristas. Lamentablemente, tenemos más de 20 veces más imágenes para este tipo de tareas, por lo que, en este momento, la precisión que hemos conseguido se limita a la limitada infraestructura de hardware necesaria para el autoaprendizaje y, aun así, superamos a los más avanzados en muchos conjuntos de datos (no en todos).
Inferencia basada en el tamaño en imágenes de estantería

Si bien hemos estado detectando marcas de diferentes productos que aparecen en las imágenes de las estanterías, una especificación reciente que hemos intentado resolver es la de razonar sobre qué variante de tamaño de un producto es el producto del que dependemos. Por ejemplo, si Computer Vision detecta un Lays Magic Masala en una estantería y lo clasifica como Lays Magic Masala, ¿cómo sabemos si se trata de una variante de 50 gramos, una variante de 100 gramos o una variante de 200 gramos del producto? Por lo tanto, incluimos una tercera tarea posterior para adivinar la variante de tamaño de la estantería. Este proceso toma las diferentes cajas extraídas de la estantería y sus marcas, y crea características que pueden usarse para adivinar el tamaño. Como es obvio, no se pueden usar las coordenadas o el área de un cuadro delimitador para razonar, ya que las imágenes se pueden tomar desde cualquier distancia. Usamos funciones como la relación de aspecto y la relación de área entre cajas de diferentes grupos para inferir la variación de tamaño.
(Papel) Enfoques de aprendizaje automático para hacer un razonamiento basado en el tamaño de los objetos de las estanterías minoristas a fin de clasificar las variantes de los productos — Enlace
Muktabh Mayani Srivastava, Pratyush Kumar
Se utilizan muchos trucos de ingeniería de características para entrenar las dos variantes de la tarea de razonamiento: usar XGBOOST sobre características agrupadas y usar una red neuronal sobre características derivadas del modelo de mezcla gaussiano.

Razonamiento sobre los materiales para puntos de venta
Cuando entras en una tienda minorista, te das cuenta de diferentes materiales POSM: tiras para estantes, recortes, pósters, gandolas y estantes de demostración.

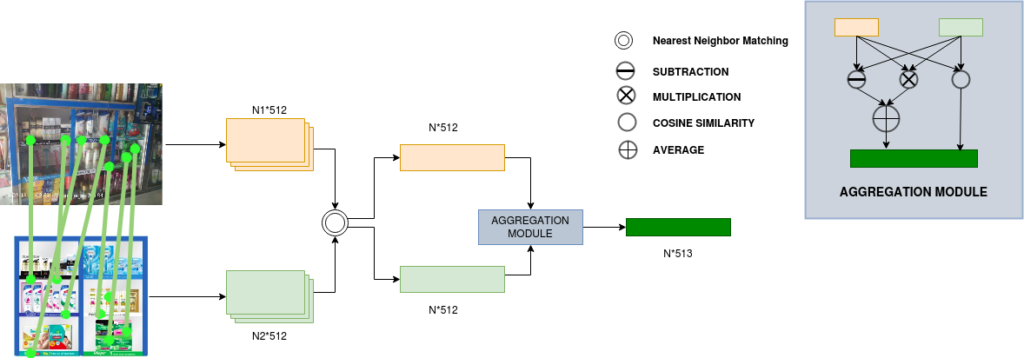
Si bien hemos estado utilizando la coincidencia de representaciones de puntos clave basada en el aprendizaje profundo para verificar la presencia de POSM en una imagen, había una tarea para razonar sobre POSM parte por parte. Es decir, en el ejemplo anterior, por ejemplo, es posible que necesitemos comprobar si la fotografía del producto que aparece a la derecha en la tira ideal de la estantería está colocada en el mundo real o no. Tras la verificación del POSM, a esto lo denominamos detección de «piezas».
(Papel) Uso de Keypoint Matching y Interactive Self Attention Network para verificar los POSM minoristas — Enlace
Harshita Seth, Sonaal Kant, Muktabh Mayank Srivastava
Básicamente, dado que el POSM cambia muy rápido semanalmente o mensualmente, nunca se puede obtener una gran cantidad de datos para entrenar algoritmos para cada POSM. Por lo tanto, necesitamos algoritmos que se entrenen de alguna manera en los conjuntos de datos existentes para que puedan aplicarse a cualquier conjunto de datos. Ese es nuestro objetivo con el reciente trabajo de la red de autoatención para POSM. Usamos puntos clave coincidentes [en una imagen POSM ideal y en una imagen real] y sus descriptores [de ambas imágenes] como entrada para cada parte por separado para determinar la presencia exacta.
Una API de análisis de opiniones que funciona con cualquier dato de dominio
Cuando entrenas un modelo para implementarlo como una API de análisis de opiniones, realmente no puedes obtener anotaciones en los datos de diferentes dominios. Por ejemplo, el modelo anterior de análisis de opiniones que teníamos consistía en un modelo lingüístico extenso que ajustaba con precisión más de 10 a 15 000 tuits impares que anotábamos internamente. Por lo tanto, el algoritmo apenas ha visto expresar sentimientos en diferentes dominios durante el aprendizaje. Intentamos utilizar el autoaprendizaje para hacer que nuestro algoritmo de clasificación de sentimientos fuera resistente a los cambios de dominio. Tomemos más de 2 millones de frases sin anotar, ejecutamos una versión anterior del clasificador para crear seudóetiquetas y entrenamos a un nuevo clasificador para que aprenda estas seudóetiquetas y listo... tenemos un clasificador de sentimientos que es mucho más robusto, mientras que su precisión en el dominio inicial sigue siendo la misma. Suena demasiado bueno para ser verdad, echa un vistazo a nuestro trabajo:
(Papel) El uso de psuedolabels para entrenar los clasificadores de sentimientos hace que el modelo se generalice mejor en todos los conjuntos de datos: Enlace
Natesh Reddy, Muktabh Mayani Srivastava
Creación de un método de última generación para detectar sentimientos específicos
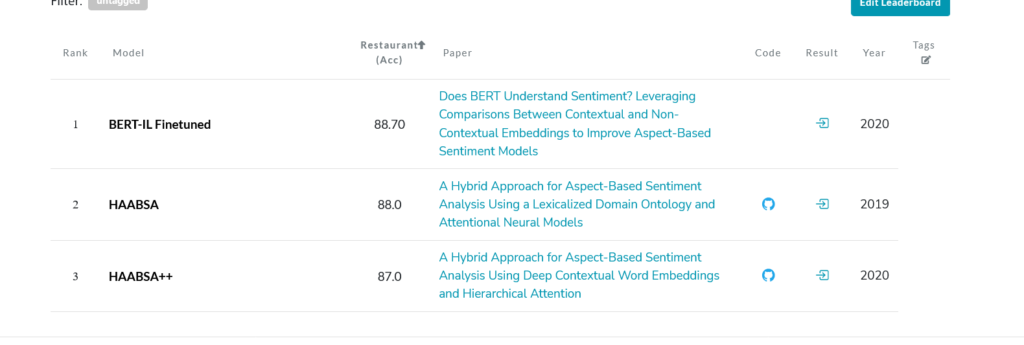
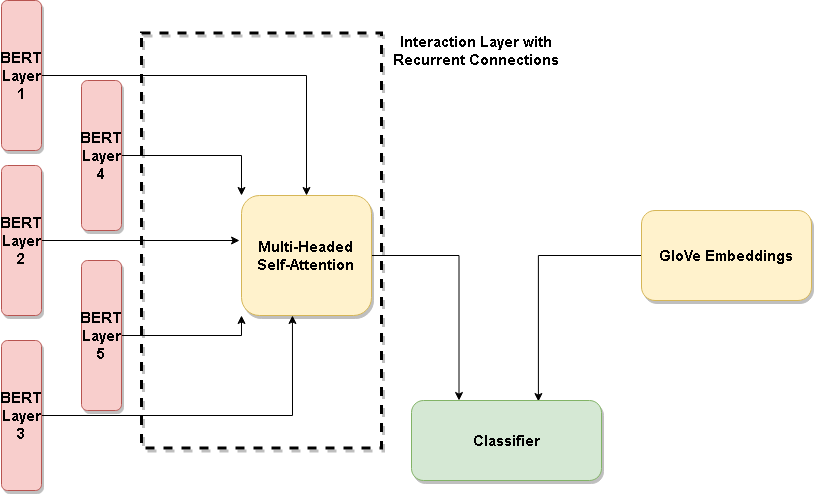
Para nosotros, en el negocio de las API de PNL, el sentimiento segmentado es cuando tienes la frase «La manzana no estaba tan sabrosa, pero la naranja estaba buena», un clasificador arroja un resultado negativo cuando se introduce «manzana» y un positivo si se introduce naranja. Básicamente, el sentimiento dirigido hacia un objeto en una oración. Hemos desarrollado un nuevo método que detecta el sentimiento segmentado y que pronto estará disponible como API de PNL. El campo de investigación corresponde al análisis de sentimientos basado en aspectos y nuestro trabajo reciente obtiene resultados de última generación en múltiples conjuntos de datos, simplemente ajustando una arquitectura que compare lo contextual [BERT] y lo no contextual [gLOve]. El sentimiento está oculto en su contexto en alguna parte, ¿verdad?
(Papel) ¿BERT entiende el sentimiento? Aprovechar las comparaciones entre las incrustaciones contextuales y no contextuales para mejorar los modelos de sentimiento basados en aspectos — Enlace
Natesh Reddy, Pranaydeep Singh, Muktabh Mayani Srivastava
Hacia adelante y hacia arriba
Espero que os haya gustado la nueva tecnología que desarrollamos el año pasado. Estaremos encantados de responder a sus preguntas si tiene alguna. Seguimos desarrollando nuevas e interesantes tecnologías y estamos trabajando en algunos nuevos problemas interesantes de aprendizaje automático, como las redes neuronales gráficas para la recomendación de minoristas, la clasificación de imágenes fuera de distribución y los modelos lingüísticos. También estamos contratando personal, escríbenos a careers@paralleldots.com o envía una solicitud a través de nuestra página AngelList para unirte a nuestro equipo de IA. Puedes postularte si quieres ser ingeniero de aprendizaje automático, desarrollador de backend o gerente de proyectos de IA. Lista de ángeles de puntos paralelos


.png)