Share it with your network.
2020 [und das erste Halbjahr 2021] war ein schwarzer Schwan. Familien, Gesellschaften und Unternehmen mussten sich mit Dingen auseinandersetzen, die sie sich nicht hätten vorstellen können. In diesem Beitrag werde ich versuchen, hervorzuheben, wie sich das KI-Team von ParallelDots in dieser Zeit angepasst und auf die nächste Generation unserer KI-Lösungen für den Einzelhandel vorbereitet hat.
ParallelDots ging im Februar 2020 in den vollständigen Remote-Arbeitsmodus über und seitdem hat sich das Team einen Tag lang nicht mehr physisch getroffen. Davor waren wir immer eine sehr eng verbundene Einheit gewesen und daher wurden die ersten Wochen ausschließlich damit verbracht, eine Kultur der Telearbeit aufzubauen. Wir mussten über eine bessere Kommunikation und eine ganz andere Eigentümerstruktur nachdenken. Angesichts der Tatsache, dass das Unternehmen auch mit einem Geschäftsschock zu kämpfen hatte, waren diese Wochen schwierig. Ich persönlich bin stolz darauf, wie unser Team mit dem Druck umgegangen ist und sich nicht nur angepasst hat, sondern sich zu der leistungsstärksten Maschine entwickelt hat, die es immer war. Nur ein paar Wochen voller Optimierungen und wir waren wieder großartig.
Herausforderungen für das KI-Team [ca. März 2020]
[Vielleicht findest du das 'Warum' der verschiedenen KI-Algorithmen und Systeme, die wir entwickeln, langweilig, ich weiß es, weil ich es getan hätte 😉, falls du nur an dem 'Wie' oder all den neuen coolen Technologien und Algorithmen interessiert bist, geh runter zum Abschnitt 'Neue Systeme und Algorithmen']
Die Rolle des KI-Teams von ParallelDots besteht darin, verschiedene Probleme zu lösen, die unsere KI-Trainings- und Bereitstellungsinfrastruktur bei ParallelDots zum Stillstand bringen. Du kannst diese Herausforderungen einteilen in: A. Engpässe in Bezug auf KI-Trainings und Genauigkeit [oder Forschungsengpässe] und B. Engpässe bei der Bereitstellung und Inferenz [oder MLOPS-Engpässe, wie wir sie nennen]. Zu Beginn des Jahres 2020, als unsere KI-Technologie bereits über eine Million Bilder pro Monat verarbeitete, sollten wir einige Herausforderungen lösen, um sie skalierbar zu machen:
- Bereitstellung einer Inferenzinfrastruktur, die automatisch skaliert werden kann für den Fall, dass zu viele Einzelhandelsimages verarbeitet werden müssen, um unsere SLAs einzuhalten und gleichzeitig sicherzustellen, dass die Bereitstellung für kleine Workloads reduziert wird. GPUs sind teure Maschinen, und eine statische [oder standardmäßige oder manuelle DevOps-] Infrastruktur ist eine Gratwanderung zwischen der Einhaltung von SLAs und der Vermeidung hoher Kosten.
- Damit unsere Computer-Vision-Algorithmen für den Einzelhandel auf dem Telefon laufen. Wir hatten uns immer ein neues Produkt ausgedacht, bei dem moderne KI im Telefon in kleinen Einzelhandelsgeschäften mit langsamer Internetverbindung für Rechnungsstellung/GRN/Bestandsverwaltung verwendet werden könnte. Nicht nur das, einige unserer potenziellen Shelfwatch-Kunden wünschten sich Installationen, die in Geschäften für schnelle Rückschlüsse verwendet werden konnten, ohne dass das Hochladen und Verarbeiten der Bilder abgewartet werden musste. Wir waren uns bewusst, dass es uns helfen würde, unser zweites Traumprodukt zu entwickeln, wenn wir unsere KI-Algorithmen für den Einzelhandel auf Telefonen ausführen könnten, aber auch unserem bestehenden Produkt helfen würde, neue Kunden zu gewinnen. Beide oben genannten Herausforderungen sind MLOPS-Herausforderungen, wie wir sie nennen.
- Erkennung von Größenvarianten von Produkten in Bildern. Eine weitere Herausforderung bestand darin, Größenunterschiede für ein Produkt in Einzelhandelsbildern zu erkennen. Nehmen wir als Beispiel an, Sie haben ein Bild für ein Regal mit Chips und müssen mithilfe von KI nicht nur die Anzahl von Lay's Magic Masala ermitteln, sondern in Ihrer Analyse auch eine Aufteilung zwischen 10 INR/ 20 INR/ 30 INR-Paketen von Lay's Magic Masala angeben. Für Leute, die noch nicht mit Computer Vision gearbeitet haben, könnte dies wie ein naheliegendes und einfaches nächstes Problem aussehen, das es zu lösen gilt, da die KI Produkte im Regal erkennen und sie mit sehr hoher Genauigkeit als Marken klassifizieren kann. Aber Sie kennen das berühmte XKCD #1425 [Es gibt immer eine relevante XKCD für alles]. Relevantes XKCD
- Überprüfung von Teilen von Point-Of-Sale-Materialien. Ein weiterer Teil der Analyse von Regalbildern ist neben der Erkennung und Identifizierung von Produkten im Regal die Überprüfung des Vorhandenseins verschiedener POS-Materialien im Regal. Bei diesen POS-Materialien handelt es sich um Dinge, die Sie häufig in einem Einzelhandels- oder Kirana-Geschäft in Ihrer Nähe sehen würden, z. B. Regalstreifen, Ausschnitte, Poster, Gandolas und Vorführregale. Wir haben Deep Keypoint Matching für solche Spiele sehr lange verwendet und es hat früher gut funktioniert. Mit der Zeit baten uns die Kunden jedoch nicht nur darum, POSM in Regalbildern zu verifizieren, sondern auch auf die fehlenden Teile hinzuweisen, die ein Merchandizer möglicherweise in einem POSM übersehen hat. Zum Beispiel könnte es sein, dass ein Merchandizer es verpasst hat, ein Poster auf einem Demo-Rack zu platzieren, oder es könnte aufgrund eines Unfalls im Geschäft entfernt worden sein. Um dies auf einer Ebene, auf der die Bildklassifizierung funktioniert, sehr genau durchzuführen, brauchten wir einen Algorithmus, der überall ohne Schulung funktioniert, da sich POSMs innerhalb von Wochen/Monaten ändern.
- Schulung genauerer Detektoren für Regalprodukte. Retail Shelf Computer Vision ist auf die Technologie umgestiegen, bei der im ersten Schritt ein generischer Regalobjektdetektor [jedes Regalobjekt herausziehen, ohne es zu klassifizieren] und dann die Produkte zu klassifizieren, die dann im zweiten Schritt extrahiert werden, um die Probleme zu vermeiden, die in einem Schritt durch Detektoren und Klassifikatoren entstehen [massive Produktschiefheit in den Regalen, was zu schlechten Klassifizierungsergebnissen führt; Schulung mit vielen Daten pro Projekt und kein zusätzlicher Gewinn, wenn die KI aus früheren Projekten besser wird usw.]. Wir hatten bereits 2019 im zweiten Schritt ein solches System aus einem generischen Regalobjektdetektor und einem hochmodernen Klassifikator, aber die Ausgabeboxformen des Regalobjektdetektors hätten besser sein können.
- Verwenden Sie früheres KI-Training und Fehlerkorrekturen, um Klassifikatoren besser und schneller zu trainieren. Wir trainieren so viele Klassifikatoren [Modelle, die Regalobjekte, die mit dem Step-1-Algorithmus extrahiert wurden, in eine der von uns benötigten Produktmarken einordnen]. Gibt es eine Möglichkeit, alle von uns gesammelten Trainingsdaten, einschließlich der Fehler früherer Klassifikatoren, zu verwenden, um einen Algorithmus zu erstellen, mit dem neue Klassifikatoren sowohl schneller als auch genauer trainiert werden können, ist eine Frage, die sich immer stellt. Die vier Forschungsprobleme [3-6], die Sie gefunden haben, spiegelten die neuen Anforderungen an unser Shelfwatch-Produkt [3,4] und die Verbesserung des bestehenden Stacks [5,6] wider. Jetzt gab es auch eine Reihe von Forschungsproblemen aus unserem NLP-API-Stack.
- Eine allgemeinere Sentimentanalyse-API. Die Stimmungsanalyse-API, die wir online hatten, wurde mit internen kommentierten Tweets trainiert und konnte daher trotz großer Genauigkeit bei domänenspezifischen Dingen wie beispielsweise politischen oder finanziellen Artikeln versagen. Im Gegensatz zu Tweets können solche Artikel aus verschiedenen Bereichen von Personen, die keine Erfahrung mit der Domain eines Datensatzes haben, nur schwer mit Anmerkungen versehen werden. Es war schon immer eine Herausforderung, viele unkommentierte Daten zu verwenden, um Klassifikatoren zu trainieren, die domänenübergreifend funktionieren könnten.
- Eine neue API für gezielte Stimmungen. Die aspektbasierte Stimmungsanalyse gibt es schon seit einiger Zeit. Wir hatten endlich einen internen, annotierten Datensatz für eine solche Analyse, aber unser Ziel war etwas spezifischer. Wir wollten eine API erstellen, bei der Sie den Satz „Der Apfel war nicht lecker, aber die Orange war wirklich lecker.“ angeben, der bei der Analyse auf „Apfel“ einen negativen Ausgang ergibt, oder positiv, wenn auf Orange analysiert wird. Wir hatten uns daher zum Ziel gesetzt, einen hochmodernen Algorithmus für die aspektbasierte Stimmungsanalyse zu entwickeln.
Nachdem ich Sie mit den Einzelheiten der Herausforderungen, die wir zu lösen versucht haben, gelangweilt habe, kommen wir zum interessanten Teil. Unsere neuen MLOPS-Plattformen und Algorithmen.
Neue Systeme und Algorithmen
Lassen Sie mich Ihnen meine neuen Freunde vorstellen, einige großartige Technologiesysteme und KI-Algorithmen, die wir in der letzten Zeit entwickelt und eingesetzt haben, um die Engpässe zu beheben.
KI zur mobilen Produkterkennung oder KI zur mobilen Regalerkennung
Einführung in ParallelDots Oogashop — Verknüpfung
Wir haben nicht nur einen, sondern zwei verschiedene Arten von KI-Algorithmen auf Mobilgeräten entwickelt und eingesetzt. Vielleicht haben Sie vor ein paar Tagen unsere extrem viralen Beiträge gesehen, in denen wir die Abrechnung von Mobiltelefonen vorgestellt und über Offline-Audits gesprochen haben.
Hier ist der Link zur On-Device Image Recognition Feature (ODIN) von ShelfWatch — Verknüpfung
(Artikel)
Im Wesentlichen handelt es sich bei diesen KI-Modellen um verkleinerte Versionen der Modelle, die wir in der Cloud bereitstellen. Mit einem gewissen Genauigkeitsverlust sind diese Modelle jetzt klein genug, um auf einer Telefon-GPU zu laufen [die viel kleiner ist als eine Server-GPU]. Die neuen Frameworks für die mobile Bereitstellung von Tensorflow verwenden wir, um diese Modelle in unserer OOGASHOP- bzw. ShelfWatch-App bereitzustellen.
(Paper) Kompakte Regalsegmentierung im Einzelhandel für den mobilen Einsatz — Verknüpfung
Pratyush Kumar, Muktabh Mayank Srivastava
Automatische Skalierung der Cloud-KI-Inferenz
Wenn die Geschäfte gegen 11 Uhr öffnen [11 Uhr für verschiedene Zeitzonen, das heißt, wo auch immer auf der Welt unsere Kunden ihre Vertriebsmitarbeiter oder Merchandizer haben], sehen sich unsere Server mit einer wahnsinnigen Menge von Merchandizern konfrontiert, die Fotos in unsere Cloud hochladen, um sie zu verarbeiten und ihnen mitzuteilen, wie viel sie im Einzelhandel erzielt haben. Und dann, nach 23 Uhr, wenn die Einzelhandelsgeschäfte schließen, haben wir kaum genug KI-Inferenz-Workload. Obwohl Lambda-ähnliches Autoscaling von vielen Anbietern eingeführt wurde, wollten wir eine Cloud-unabhängige Autoscaling-Technik für unsere KI-Inferenzinfrastruktur. Wenn sich mehr Bilder in unserer Verarbeitungswarteschlange befinden, benötigen wir mehr GPUs, die sie verarbeiten, andernfalls nur eine oder vielleicht keine. Zu diesem Zweck wurde die gesamte KI-Inferenzschicht auf eine auf Docker, Kubernetes und KEDA basierende Architektur verschoben, wo je nach Arbeitslast eine beliebige Anzahl neuer GPUs erzeugt werden kann. Keine Gratwanderung mehr, bei der versucht wird, das SLA des Unternehmens zu verwalten und Geld für die kostspieligen GPU-Maschinen zu sparen.
Verbesserung der Algorithmen zur Erkennung von Regalobjekten
(Fachartikel) Gaußsche Karten für die Erkennung dichter Objekte lernen — Verknüpfung
Sonal Kant
Wir hatten zuvor einfache Faster RCNNs verwendet, die für die Extraktion von Regalobjekten trainiert wurden: Grundlagenpapier zur einfachen Objekterkennung . Es hat für viele Anwendungsfälle gut funktioniert. Aber wir brauchten mehr modernste Ansätze. Im Jahr 2020 entdeckte unser Team eine neue Methode zur Verwendung von Gaussian Maps, um Ergebnisse auf dem neuesten Stand der Technik zu erzielen. Diese Arbeit wurde [später] auf der BMVC, einer der wichtigsten Computer Vision-Konferenzen, veröffentlicht. BMVC-Webseite ] hat uns geholfen, nicht nur zufriedenstellende, sondern auch die bestmöglichen Ergebnisse bei der Erkennung von Regalobjekten zu erzielen.
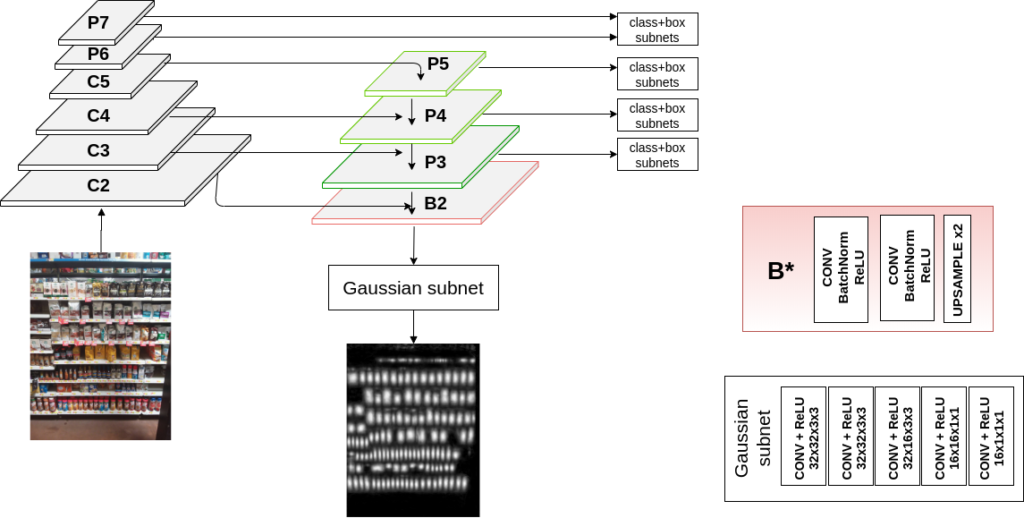
Der Trick besteht im Wesentlichen darin, das Gauß-Maps-Training als zusätzlichen Verlust bei der Objekterkennung zu verwenden. Dies macht die Boxen für verschiedene Produkte viel präziser.
Eine weitere Frage, die wir in Bezug auf die Erkennung von Regalobjekten seit langem zu beantworten versuchen, war, die Notwendigkeit, Produkte zu erkennen, in eine nachgelagerte Aufgabe verlagert wurde und die Aufgabe darin besteht, Kartons über alle möglichen Produkte zu ziehen, ob es eine Möglichkeit gibt, die Geräusche und Verzerrungen, die in einem riesigen Datensatz ohne Anmerkungen enthalten sind, für eine bessere Erkennung von Regalobjekten zu nutzen. In einer kürzlich erschienenen Arbeit [erwähnt unter RetailVision-Workshop auf der CVPR 2021 Workshop zur Vision des Einzelhandels ] verwenden wir unser riesiges Archiv an Regalbildern ohne Anmerkungen, um die Genauigkeit der Aufgabe zur Erkennung von Regalobjekten zu verbessern.
(Fachartikel) Halbüberwachtes Lernen zur Erkennung dichter Objekte in Einzelhandelsszenen — Verknüpfung
Jaydeep Chauhan, Srikrishna Varadarajan, Muktabh Mayank Srivastava
Die auf Pseudo-Labels basierende Schulung von Schülern ist ein Trick, den wir in mehreren Bereichen angewendet haben, nicht zur Erkennung von Regalobjekten. Während andere Selbstlerntechniken erfordern, dass große Batchgrößen auf GPUs geladen werden, was es für Unternehmen wie begrenzte Hardware wie ParallelDots schwierig macht, sie auszuprobieren, haben wir Pseudo-Labels als unseren Trick angepasst, um das Selbstlernen einzelner GPUs durchzuführen.
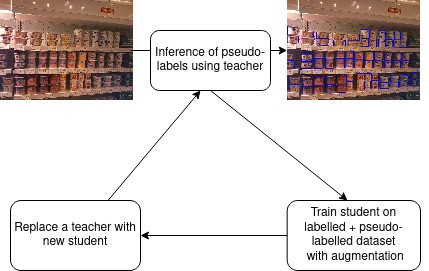
Bessere Klassifikationsgenauigkeit
Wir haben in der Vergangenheit mehrere Tricks verwendet, um genaue Klassifikatoren mit hoher Genauigkeit zu trainieren.
(Papier-) Trickkiste zur Klassifizierung von Einzelhandelsprodukten — Verknüpfung, was zeigt, wie wir Klassifikatoren mit hoher Genauigkeit trainieren.
Muktabh Mayank Srivastava
Alle Kartons, die der Regalobjektdetektor aus einem Regalbild extrahiert, durchlaufen diesen Klassifikator, um auf die Produktmarke zu schließen.

Angesichts der häufig wechselnden Kataloge der Geschäfte muss sich unser Produktklassifikator jedoch weiterentwickeln, um die Dinge ein bisschen anders zu machen. Das Training eines Klassifikators ist ressourcenintensiv, da Produkte schnell in die Kataloge der Filialen aufgenommen oder aus ihnen entfernt werden. Deshalb benötigen wir einen Klassifikator, der schnell trainiert werden kann und der genauer oder mindestens genauso genau ist wie die Methoden, die die Feinabstimmung des gesamten Rückgrats beinhalten. Das klingt, als ob man alles auf einmal haben und bewerten muss, und genau das ist es, was Techniken des Selbstlernens im Deep Learning bewiesen haben. Wir haben versucht, Konzepte des Selbstlernens zu verwenden, um Klassifikatoren zu erstellen, die sehr leicht trainiert werden können.
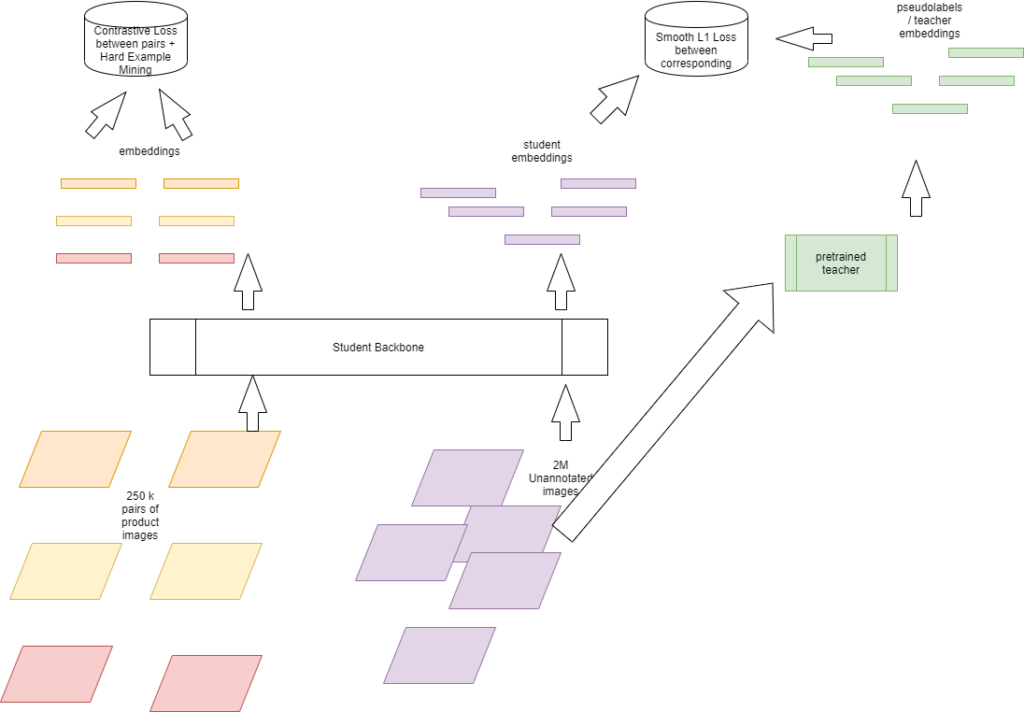
(Artikel) Verwendung von kontrastivem Lernen und Pseudolabels zum Erlernen von Repräsentationen für die Klassifizierung von Produktbildern im Einzelhandel — Verknüpfung
Muktabh Mayank Srivastava
Der Trick, den wir hier anwenden, besteht darin, den riesigen Bestand an Bildern von Einzelhandelsprodukten, die wir haben [sowohl mit Anmerkungen als auch ohne Anmerkungen], zu verwenden, um einen Repräsentationslerner zu schulen, dessen Ergebnisse zu Trainingszwecken in einen einfachen Klassifikator für maschinelles Lernen eingespeist werden können. Solche erlernten Merkmalsdarstellungen funktionieren recht gut. Wie cool ist es, einen kleinen logistischen Regressionsklassifikator zu trainieren, um Bilder aus dem Einzelhandel zu klassifizieren. Leider haben wir mehr als 20-mal mehr Bilder für solche Aufgaben, daher ist unsere erreichte Genauigkeit derzeit auf die begrenzte Hardware-Infrastruktur beschränkt, um solche Selbstlernvorgänge durchzuführen, und trotzdem übertreffen wir den Stand der Technik bei vielen [nicht allen] Datensätzen.
Größenbasierte Inferenz auf Regalbildern

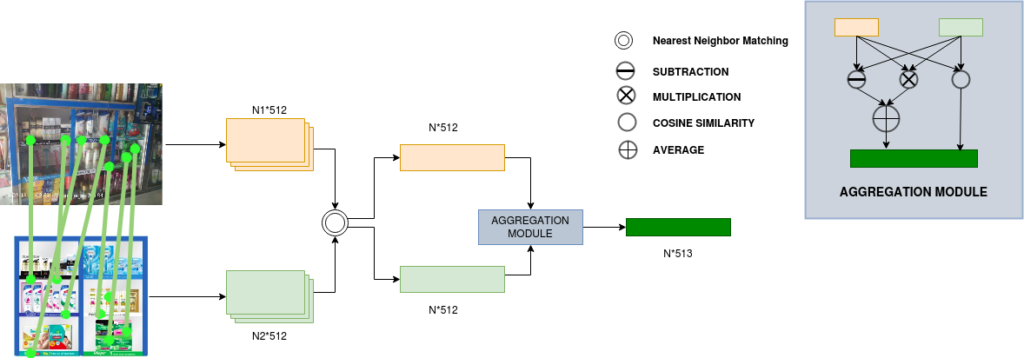
Wir haben zwar verschiedene Marken verschiedener Produkte auf den Regalbildern entdeckt, aber eine aktuelle Spezifikation, die wir zu lösen versucht haben, ist die Überlegung, welche Größenvariante eines Produkts das Produkt ist, von dem wir abhängig sind. Während die Computer Vision-Pipeline beispielsweise ein Lays Magic Masala im Regal erkennt und es als Lays Magic Masala einstuft, wissen wir aber, ob es sich um eine 50-Gramm-Variante, eine 100-Gramm-Variante oder eine 200-Gramm-Variante des Produkts handelt. Wir schließen daher eine dritte nachgelagerte Aufgabe ein, um die Größenvariante des Regals zu erraten. Diese Pipeline verwendet die verschiedenen Boxen, die aus dem Regal entnommen wurden, und ihre Marken und erstellt Merkmale, anhand derer die Größe erraten werden kann. Es liegt auf der Hand, dass Sie aus solchen Gründen keine Koordinaten oder Flächen von Bounding-Boxes verwenden können, da Bilder aus beliebiger Entfernung aufgenommen werden können. Wir verwenden Funktionen wie das Seitenverhältnis und das Flächenverhältnis zwischen Boxen verschiedener Gruppen, um Größenvarianten abzuleiten.
(Fachartikel) Machine-Learning-Ansätze zur Größenberechnung von Retail Shelf-Objekten zur Klassifizierung von Produktvarianten — Verknüpfung
Muktabh Mayank Srivastava, Pratyush Kumar
Um die beiden Varianten der Argumentationsaufgabe zu trainieren, kommen viele Tricks des Feature-Engineerings zum Einsatz: Die Verwendung von XGBOOST über Merkmale in Gruppen und die Verwendung eines neuronalen Netzwerks über dem Gaußschen Mischungsmodell abgeleitete Merkmale.

Überlegungen zu POS-Materialien
Wenn Sie ein Einzelhandelsgeschäft betreten, werden Ihnen verschiedene POSM-Materialien auffallen: Regalleisten, Ausschnitte, Poster, Gandolas und Demo-Racks.

Wir haben zwar Deep-Learning-basiertes Keypoint-Repräsentations-Matching verwendet, um das Vorhandensein von POSM in einem Bild zu überprüfen, aber es gab die Aufgabe, POSM Teil für Teil zu analysieren. Das ist beispielsweise im obigen Beispiel der Fall. Möglicherweise müssen wir überprüfen, ob das Produktfoto auf der rechten Seite im idealen Regalstreifen auf einer realen Platzierung vorhanden ist oder nicht. Wir nennen das nach der POSM-Verifizierung eine „Teileerkennung“.
(Artikel) Verwendung von Keypoint Matching und Interactive Self Attention Network zur Überprüfung von POSMs im Einzelhandel — Verknüpfung
Harshita Seth, Sonaal Kant, Muktabh Mayank Srivastava
Da sich POSM wöchentlich/monatlich sehr schnell ändert, können Sie im Wesentlichen nie viele Daten abrufen, um Algorithmen für jedes POSM zu trainieren. Wir benötigen also Algorithmen, die in gewisser Weise an vorhandenen Datensätzen trainiert werden, sodass sie auf jeden Datensatz angewendet werden können. Das ist unser Ziel mit der jüngsten Arbeit von Self Attention Network for POSms. Wir verwenden übereinstimmende Keypoints [auf dem idealen POSM-Bild und dem echten Wortbild] und ihre Deskriptoren [aus beiden Bildern] als Eingabe für jeden Teil separat, um die genaue Präsenz zu bestimmen.
Eine Sentimentanalyse-API, die mit beliebigen Domaindaten funktioniert
Wenn Sie ein Modell so trainieren, dass es als Stimmungsanalyse-API eingesetzt werden soll, können Sie nicht wirklich Daten aus verschiedenen Domänen mit Anmerkungen versehen. Zum Beispiel war das vorherige Modell der Stimmungsanalyse, das wir hatten, ein großes Sprachmodell, das über 10 bis 15.000 Tweets, die wir intern kommentiert haben, fein abgestimmt hat. Der Algorithmus hat also während des Lernens kaum Stimmungen gesehen, die in verschiedenen Bereichen zum Ausdruck kamen. Wir haben versucht, mithilfe von Selbstlernen unseren Algorithmus zur Stimmungsklassifizierung robust gegenüber Domänenänderungen zu machen. Nehmen wir mehr als 2 Millionen Sätze ohne Anmerkungen, lassen Sie eine ältere Version des Klassifikators laufen, um Pseudo-Labels zu erstellen, und trainieren Sie einen neuen Klassifikator, der diese Pseudo-Labels lernt, und schon haben Sie einen Stimmungsklassifikator, der viel robuster ist, während seine Genauigkeit im ursprünglichen Bereich gleich bleibt. Klingt zu schön um wahr zu sein, schauen Sie sich unsere Arbeit an:
(Artikel) Durch die Verwendung von Pseudolabels für das Training von Stimmungsklassifikatoren lässt sich das Modell besser über Datensätze hinweg verallgemeinern — Verknüpfung
Natesh Reddy, Muktabh Mayank Srivastava
Entwicklung einer hochmodernen Methode zur Erkennung gezielter Stimmungen
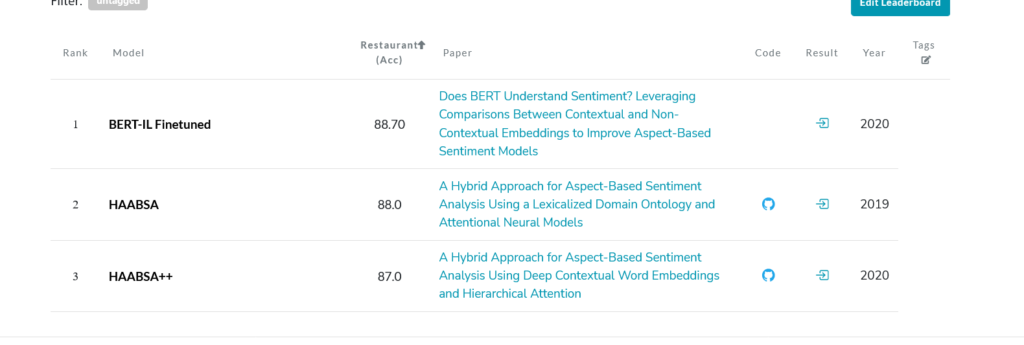
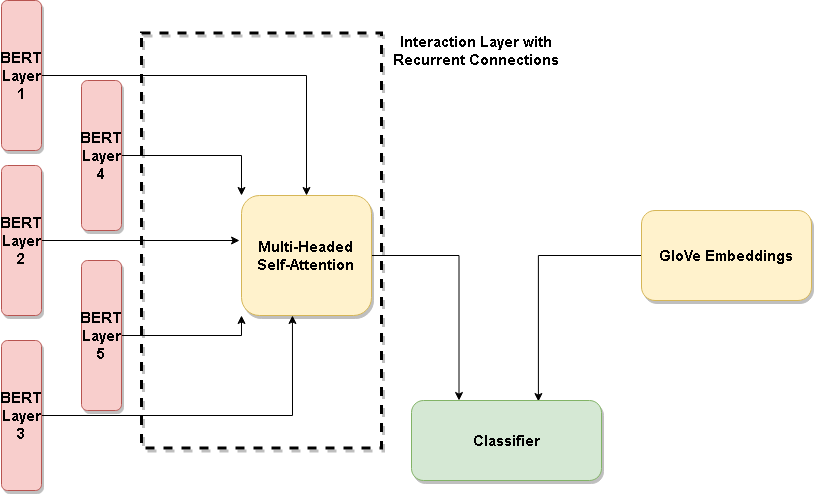
Für uns im NLP-API-Geschäft bedeutet gezielte Stimmung, wenn Sie den Satz „Apple war nicht so lecker, aber Orange war gut“ haben. Ein Klassifikator gibt negativ zurück, wenn er die Eingabe „Apfel“ erhält, und positiv, wenn er Orange erhält. Im Grunde genommen handelt es sich um eine Stimmung, die auf ein Objekt in einem Satz gerichtet ist. Wir haben eine neue Methode entwickelt, die gezielte Stimmungen erkennt und die bald als NLP-API verfügbar sein wird. Das Forschungsfeld entspricht der aspektbasierten Stimmungsanalyse, und unsere jüngste Arbeit liefert modernste Ergebnisse in mehreren Datensätzen, indem einfach eine Architektur verfeinert wird, die kontextuelles [BERT] und nicht-kontextuelles [GLOVE] vergleicht. Das Gefühl ist irgendwo im Kontext versteckt, oder?
(Artikel) Versteht BERT Stimmungen? Nutzung von Vergleichen zwischen kontextuellen und nicht-kontextuellen Einbettungen zur Verbesserung aspektbasierter Stimmungsmodelle — Verknüpfung
Natesh Reddy, Pranaydeep Singh, Muktabh Mayank Srivastava
Vorwärts und aufwärts
Ich hoffe, Ihnen hat die neue Technologie gefallen, die wir letztes Jahr entwickelt haben. Sehr gerne beantworten wir Ihre Fragen, falls Sie welche haben. Wir entwickeln weiterhin neue und spannende Technologien und arbeiten an einigen neuen coolen maschinellen Lernproblemen wie neuronale Graphnetzwerke für Einzelhandelsempfehlungen, Out-Of-Distribution Image Classification und Sprachmodellen. Wir stellen ebenfalls ein, schreiben Sie uns an careers@paralleldots.com oder bewerben Sie sich auf unserer AngelList-Seite, um unserem KI-Team beizutreten. Du kannst dich bewerben, wenn du Machine Learning Engineer, Backend-Entwickler oder KI-Projektmanager werden möchtest. ParallelDots AngelList


.png)