Share it with your network.
El Banco Mundial organizó su concurso de predicción de la pobreza en el sitio web de alojamiento del concurso drivens.org. El enlace al concurso es aquí. Decidimos probar nuestras habilidades de aprendizaje automático en este conjunto de datos. La mayoría de los trabajos habituales se realizan en Puntos paralelos gira en torno a tres temas: análisis visual de imágenes y vídeos, IA sanitaria y PNL, los tres se resuelven mediante técnicas de aprendizaje profundo. Este concurso fue una oportunidad para probar algo nuevo y crear nuestra base de código interna para gestionar conjuntos de datos tabulares como los que teníamos en el concurso.
Los resultados finales que queríamos obtener de la competencia:
- Pruebe una multitud de modelos de aprendizaje automático que podrían resolver el problema.
- Pruebe los métodos AutoML existentes. (Los métodos de AutoML solo necesitan que trabajes con un ingeniero de funciones y descubras el resto del proceso por sí solo)
- Cree el mejor modelo para resolver el problema sin tener que armar demasiados modelos y mejorar las puntuaciones. Dado que la AIaaS es nuestro trabajo diario, la optimización para un buen modelo es más importante para nosotros, ya que los conjuntos son difíciles de implementar como servicios.
- Cree un repositorio de código para abordar los problemas de ciencia de datos y aprendizaje automático en el futuro.
Analizar el conjunto de datos (sin mucho esfuerzo)
La primera tarea, como en cualquier proyecto de aprendizaje automático, es analizar los conjuntos de datos y ver sus propiedades. Parte de la información que podemos obtener al observar el conjunto de datos es:
- Hay archivos de datos para tres países diferentes.
- Todos los campos están anonimizados y codificados, por lo que no sabe lo que significan los campos. Esto reduce a cero cualquier posibilidad de ingeniería de funciones específicas de un dominio.
- Los datos de los tres países son totalmente diferentes, por lo que es necesario crear tres modelos, uno para cada país.
Una forma de profundizar en los datos (rápidamente) es usar el nuevo paquete Pandas-Profiling (que se puede descargar desde GitHub) aquí). Este paquete realiza muchos análisis primarios y los guarda como bonitos archivos HTML que se pueden ver en su navegador. Hicimos Pandas-Profiling con los datos de los tres países para conocer los tipos de datos, las frecuencias, la correlación, etc.
Los resultados de muestra de uno de los países se pueden ver en la siguiente imagen:
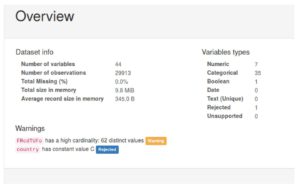
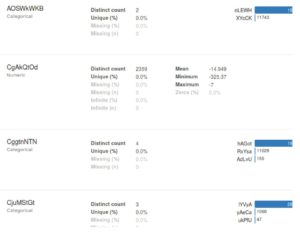

Algunas conclusiones más que podemos sacar son:
- Parece que hay un valor predeterminado para la mayoría de los campos categóricos que es el valor más común del campo. (En la imagen de arriba, por ejemplo, puedes ver que el campo AOSwKWKB tiene un valor predeterminado que se utiliza más del 80% de veces)
- Los conjuntos de datos están muy desequilibrados, por lo que debemos tener en cuenta este hecho durante el entrenamiento.
Dos formas de modelar los datos
Si se observan los tipos de datos de los objetos, se puede ver que los datos son una combinación de valores categóricos (atributos que pueden extraer uno de un número constante de valores enumerables) y valores numéricos (tanto flotantes como enteros). De hecho, así es como se modela y está disponible el punto de referencia Random Forest proporcionado por el Banco Mundial aquí. Sin embargo, si nos fijamos en las cantidades numéricas, no son muy numerosas y pueden representar cantidades como la fecha de nacimiento, etc. (si has realizado el curso de Coursera, Dmitry menciona un conjunto de campos similar en la sección sobre el manejo de conjuntos de datos anónimos). Por eso, otro enfoque que queríamos probar era tratar todos los campos como atributos categóricos. Al final, probamos ambos.
Desequilibrio de datos
Otra propiedad importante del conjunto de datos es el desequilibrio entre las clases +ve y -ve (las personas que no son pobres superan ampliamente en número a las personas pobres). Para el país A, los datos siguen siendo equilibrados, pero para el B y el C, los datos tienen una distribución muy sesgada. Para entrenar modelos con datos tan sesgados, probamos diferentes enfoques utilizando una biblioteca de aprendizaje desequilibrado en Python:
- Entrenamiento sobre el conjunto de datos sesgado (que funcionó bien, no demasiado bien)
- Entrenamiento en un conjunto de datos con una clase negativa submuestreada (lo que tuvo un desempeño muy malo, incluso los mejores modelos de aprendizaje automático podrían funcionar tan bien como la línea de base con este conjunto de datos)
- Sobremuestreo de la clase +ve (que funcionó bastante bien)
- Sobremuestreo mediante algoritmos SMOTE (no funcionó tan bien como el sobremuestreo normal, principalmente porque el algoritmo SMOTE no está realmente definido para los atributos categóricos)
- Sobremuestreo con ADASYN (no funcionó tan bien como el sobremuestreo normal)
Preprocesamiento
El conjunto de datos se preprocesó de la siguiente manera:
- Todas las características categóricas se convirtieron en funciones binarias.
- Los valores numéricos se normalizaron. Se probaron tanto la normalización máxima mínima como la media estándar.
- Los datos a nivel de hogar y a nivel individual se fusionaron (los datos a nivel individual tenían datos separados para cada miembro de todos los hogares proporcionados). Solo se conservaron los datos a nivel de hogar para los atributos comunes a los datos individuales y de los hogares. Todas las características numéricas del hogar se calcularon con una media de (lo que podría no haber sido la mejor manera) y todos los valores categóricos se sumaron hasta obtener el valor más impar del hogar (por ejemplo, si la característica X tuviera un valor de 1,1,1,0 en el hogar, tomaríamos el valor combinado del hogar como 0). El motivo es que muchas variables categóricas contienen el valor predeterminado y esperábamos que el valor impar tuviera más información.
Enfoques que probamos
Ahora hablamos de los múltiples enfoques que probamos.
- En primer lugar, hablamos de cosas que no funcionaron:
- Pensamos que los atributos predeterminados de los campos categóricos podrían no ser útiles para el modelado. Para comprobar esto, hemos entrenado modelos de aprendizaje automático con y sin los atributos predeterminados. Los modelos a los que no se les proporcionaban los atributos predeterminados consistentemente tenían peores resultados que los que se alimentaban con los valores predeterminados.
- El sobremuestreo de SMOTE y ADASYN no dio mejores resultados que el sobremuestreo normal.
- Aprendizaje automático en dos etapas: la primera para crear un árbol de decisiones para entender la importancia de las funciones y la otra para capacitar sobre las funciones más importantes. No obtuvimos ningún beneficio al probar esta técnica.
- Probar diferentes métodos para normalizar los datos numéricos no modificó la precisión. Sin embargo, la precisión de los atributos numéricos no normalizados fue peor.
- Los trucos que nos ayudaron a aumentar nuestra puntuación:
- La combinación de características numéricas y categóricas funcionó mejor para entrenar algoritmos que todos los atributos categóricos. Al menos para los árboles de decisión.
- La elección de los valores predeterminados para los datos faltantes nos ayudó a mejorar nuestra precisión. Empezamos por convertir todos los valores faltantes en cero, pero más tarde utilizamos -999, que funcionó mejor.
- La búsqueda en cuadrícula a través de hiperparámetros de aprendizaje automático nos permitió mejorar entre un 2 y un 4% en el conjunto de validaciones sin esfuerzo.
- Una base sólida de AutoML nos ayuda a empezar bien.
- Los trucos que queríamos probar pero no pudimos, no lo hicimos o fueron demasiado vagos para programar:
- Ingeniería de características tomando el producto cartesiano de valores categóricos no predeterminados y, a continuación, eligiendo las características importantes para entrenar el modelo.
- Ingeniería de características mediante la combinación de características numéricas de diferentes maneras y la selección de características en las entidades generadas.
- Probando conjuntos de varios modelos. Anteriormente nos habíamos fijado el objetivo de conseguir un buen modelo, pero aun así terminamos entrenando muchos métodos. Podríamos haberlos combinado como un conjunto, como apilarlos.
Algoritmos de aprendizaje automático



Bibliotecas que utilizamos: SKLearn, XGBOOST y TPOT
Ahora hablaremos sobre los enfoques de aprendizaje automático que probamos. Hablemos de las cosas en orden cronológico, es decir, en qué orden probamos los enfoques. Ten en cuenta que todos los trucos que nos funcionaron no estaban disponibles desde el primer intento y los hemos incluido uno por uno. Consulta los puntos de cada prueba para saber cuál era el proceso en ese momento. Todos los modelos de aprendizaje automático utilizados procedían de Biblioteca Scikit Learn a menos que se indique lo contrario.
- Los sospechosos habituales con parámetros predeterminados
- Empezamos probando los sospechosos habituales con los parámetros predeterminados. Regresión logística, SVM y Random Forests. También probamos una nueva biblioteca llamada CATBOOST, pero no pudimos encontrar mucha documentación sobre sus hiperparámetros ni podíamos adaptarla bien a los datos, así que decidimos sustituirla por la más conocida XGBOOST. También teníamos conocimientos sobre el ajuste de hiperparámetros de XGBOOST (algo que sabíamos que teníamos que hacer en etapas posteriores).
- El primer intento modeló todas las columnas como datos categóricos y conjuntos de datos desequilibrados.
- Todos los modelos se ajustan bien y nos brindan una precisión mucho mejor que el lanzamiento de monedas en los datos de validación. En cierto modo, eso nos indica que el proceso de extracción de datos está bien (no tiene errores obvios, pero hay que ajustarlo más).
- Al igual que la línea base proporcionada por los proveedores de la competencia, Random Forests y XGBOOST con hiperparámetros predeterminados muestran buenos resultados.
- LR y SVM pueden modelar bien los datos (no tan bien como RF y XGBOOST debido a la menor varianza en los hiperparámetros predeterminados). SVM (SKLearn SVC) también tenía una buena precisión, pero las probabilidades que arroja no son realmente utilizables en SKLearn (lo que descubrí que es un problema común con las opciones predeterminadas) hiperparámetros), lo que nos hizo dejar de lado la SVM, ya que la competencia juzgaba según la media loglosa, lo que requeriría un esfuerzo adicional para asegurarnos de que los números de probabilidad son correctos. Lo que pasa es que las probabilidades que SVC devuelve no son exactamente probabilidades, sino algún tipo de puntuación.
- TPOT: AutoML es una buena base
- Continuando con todas las funciones consideradas categóricas, intentamos ajustar una línea base mediante un método AutoML llamado POTE.
- TPOT usa algoritmos genéticos para determinar una buena canalización de aprendizaje automático para el problema en cuestión y qué hiperparámetros usar con él.
- Esto nos situó entre los 100 mejores de la clasificación pública del concurso en el momento en que lo presentamos.
- El TPOT tarda tiempo en determinar la canalización y convergió en unas pocas horas para todo el conjunto de datos.
- ¿Se pueden usar redes neuronales? ¿Alguien quiere redes neuronales?
El amor que sentimos por el aprendizaje profundo hizo que nos picaran las manos por probar algo parecido a las redes neuronales. Nos propusimos entrenar un buen algoritmo de redes neuronales que también pudiera resolver este problema. Tenga en cuenta que en ese momento estábamos haciendo experimentos considerando que todas las columnas eran categóricas. ¿Qué es un problema que tiene muchas variables categóricas y necesita predecir una etiqueta? Clasificación de textos. Ese es un lugar donde las redes neuronales brillan mucho. Sin embargo, a diferencia del texto, este conjunto de datos no tiene el concepto de secuencia, por lo que decidimos usar una red neuronal común en la clasificación de textos, pero sin tener en cuenta el orden. Ese algoritmo es Texto rápido. Escribimos una versión (profunda) del texto rápido, como el algoritmo de keras, para entrenar con el conjunto de datos. Otra cosa que hicimos para entrenar a Neural Network fue sobremuestrear a una clase minoritaria, ya que no funcionaba bien con datos desequilibrados.
[caption id="attachment_3089" align="alignnone» width="727"]
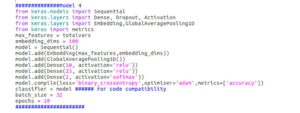
FFNN usado [/caption]
Intentamos entrenar utilizando las redes neuronales autornormalizadas propuestas recientemente. Esto nos dio un aumento de precisión en el conjunto de validación.
[caption id="attachment_3090" align="alignnone» width="746"]
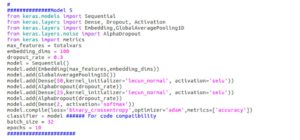
FFNN autonomalizado (SELU) que utilizamos [/caption]
Aunque obtenemos ganancias en la precisión en el conjunto de validación cuando utilizamos redes neuronales profundas, especialmente. El país B, en el que la mayor precisión que hemos obtenido (incluso mejor que la de nuestro modelo con mejores resultados) fue el uso de una red neuronal profunda autonomalizada, los resultados no se reflejan en la clasificación, donde seguimos obteniendo puntuaciones bajas (alto brillo).
- Hacia la mejora de la línea de base de AutoML y el ajuste de XGBOOST
La línea base de AutoML que creamos todavía nos miraba a la cara, ya que todos nuestros métodos artesanales eran aún peores. Por lo tanto, decidimos cambiar a los probados modelos XGBOOST para mejorar las puntuaciones. Creamos una canalización de datos para probar los diferentes trucos que hemos mencionado (con éxito o sin éxito) al principio del segmento y una canalización para buscar en cuadrículas diferentes hiperparámetros e intentar una validación cruzada de 5 veces.
[caption id="attachment_3091" align="alignnone» width="739"]

Ejemplo de búsqueda en cuadrícula para el conjunto de validación único [/caption]
Los trucos anteriores, combinados con Grid Search, dieron un gran impulso a nuestras puntuaciones y pudimos superar la puntuación de 0.2 logloss y luego también de 0.9 logloss. Probamos con otro AutoML de TPOT con un conjunto de datos generado por nuestros trucos exitosos, pero solo lo logramos con cerca de 0,2 puntos en la clasificación. Al final, el modelo XGBOOST resultó ser el mejor. No pudimos obtener la misma precisión en el mismo orden cuando intentamos realizar una búsqueda cuadriculada sobre los parámetros de un algoritmo de bosque aleatorio.
Nuestra puntuación/clasificación empeoró ligeramente en la clasificación privada en comparación con la clasificación de la competencia pública. Terminamos la competición en torno al percentil 90.
Esperamos que os haya gustado el artículo. Por favor Inscríbase para obtener una cuenta Komprehend gratuita para comenzar su viaje con la IA. También puedes consultar las demostraciones de las API de IA de Komprehend aquí.


.png)