Share it with your network.
Die Weltbank veranstaltete ihren Wettbewerb zur Armutsprognose auf der Website drivendata.org zum Hosting von Wettbewerben. Der Link zum Wettbewerb lautet hier. Wir haben beschlossen, unsere Fähigkeiten im Bereich des maschinellen Lernens an diesem Datensatz auszuprobieren. Die regulärste Arbeit in Parallele Punkte dreht sich um drei Themen: Visual Analytics für Bilder und Videos, KI im Gesundheitswesen und NLP, die alle drei mithilfe von Deep-Learning-Techniken gelöst werden. Dieser Wettbewerb war eine Gelegenheit, etwas Neues auszuprobieren und unsere interne Codebasis aufzubauen, um tabellarische Datensätze zu verarbeiten, wie wir sie im Wettbewerb hatten.
Die Endergebnisse, die wir mit dem Wettbewerb erzielen wollten:
- Probieren Sie eine Vielzahl von Modellen für maschinelles Lernen aus, mit denen das Problem möglicherweise gelöst werden kann.
- Probieren Sie bestehende AutoML-Methoden aus. (Bei AutoML-Methoden müssen Sie lediglich einen Feature-Engineer erstellen und den Rest der Pipeline selbst herausfinden)
- Erstellen Sie ein bestes Modell, um das Problem zu lösen, ohne zu viele Modelle zusammenzustellen und die Punktzahlen zu verbessern. Da AIaaS unsere tägliche Arbeit ist, ist die Optimierung für ein gutes Modell für uns wichtiger, da Ensembles schwer als Dienste bereitzustellen sind.
- Erstellen Sie ein Code-Repository, um zukünftige Probleme in den Bereichen Datenwissenschaft und maschinelles Lernen anzugehen.
Analyse des Datensatzes (ohne viel Schweiß)
Die erste Aufgabe besteht wie bei jedem Machine-Learning-Projekt darin, die Datensätze zu analysieren und ihre Eigenschaften zu sehen. Einige Informationen, die wir direkt aus dem Datensatz ableiten können, sind:
- Es gibt Datendateien für drei verschiedene Länder.
- Alle Felder sind anonymisiert und codiert, sodass Sie nicht wissen, was die Felder bedeuten. Dadurch wird die Wahrscheinlichkeit eines domänenspezifischen Feature-Engineerings auf Null reduziert.
- Die Daten für alle drei Länder sind völlig unterschiedlich, daher muss man drei Modelle erstellen, eines für jedes Land.
Eine Möglichkeit, (schnell) tiefer in Daten einzutauchen, ist die Verwendung des neuen Pakets Pandas-Profiling (das von GitHub heruntergeladen werden kann) hier). Dieses Paket führt viele Primäranalysen durch und speichert sie als hübsche HTML-Dateien, die man in ihrem Browser ansehen kann. Wir haben Pandas-Profiling mit den Daten aller drei Länder durchgeführt, um mehr über die Datentypen, Frequenzen, Korrelationen usw. zu erfahren.
Die Beispielausgabe für eines der Länder ist in der folgenden Abbildung zu sehen:
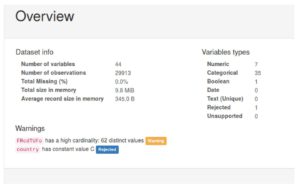
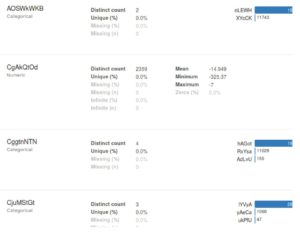

Einige weitere Schlussfolgerungen, die wir ziehen können, sind:
- Für die meisten kategorialen Felder scheint es einen Standardwert zu geben, der der gebräuchlichste Wert für das Feld ist. (Im obigen Bild können Sie zum Beispiel sehen, dass das Feld aoswkwKB einen Standardwert hat, der mehr als 80% mal benötigt wird)
- Die Datensätze sind sehr unausgewogen, wir müssen uns beim Training darum kümmern.
Zwei Möglichkeiten, die Daten zu modellieren
Wenn man sich die Datentypen der Objekte ansieht, kann man sehen, dass es sich bei den Daten um eine Mischung aus kategorialen (Attribute, die einen aus einer konstanten Anzahl von aufzählbaren Werten nehmen können) und numerischen Werten (sowohl Gleitkommazahlen als auch Ganzzahlen) handelt. Genau auf diese Weise wird der Random Forest-Benchmark von WorldBank-Modellen bereitgestellt und ist auch verfügbar hier. Wenn Sie sich jedoch die numerischen Mengen ansehen, sind sie nicht so zahlreich und könnten Größen wie Geburtsdatum usw. darstellen. (Wenn Sie den Coursera-Kurs besucht haben, spricht Dmitry im Abschnitt Umgang mit anonymisierten Datensätzen über eine ähnliche Gruppe von Feldern). Ein weiterer Ansatz, den wir ausprobieren wollten, bestand darin, alle Felder als kategoriale Attribute zu behandeln. Am Ende haben wir beide ausprobiert.
Datenungleichgewicht
Eine weitere wichtige Eigenschaft des Datensatzes ist das Ungleichgewicht zwischen den Klassen +ve und -ve (nicht arme Menschen sind den armen Menschen zahlenmäßig weit überlegen). Für Land A sind die Daten immer noch ausgewogen, aber für B und C weisen die Daten eine sehr verzerrte Verteilung auf. Um Modelle mit solchen verzerrten Daten zu trainieren, haben wir verschiedene Ansätze ausprobiert, indem wir eine Bibliothek mit unausgewogenem Lernen in Python verwendeten:
- Training mit dem schiefen Datensatz (was gut funktioniert hat, nicht so toll)
- Training mit einem Datensatz mit negativer Klassenunterabtastung (was sehr schlecht abschneidet, selbst die besten Machine-Learning-Modelle könnten mit diesem Datensatz genauso gut funktionieren wie der Ausgangswert)
- Überabtastung der +ve-Klasse (Was ganz gut funktioniert hat)
- Überabtastung mit SMOTE-Algorithmen (funktionierte nicht so gut wie normales Oversampling, hauptsächlich weil der SMOTE-Algorithmus nicht wirklich für kategoriale Attribute definiert ist)
- Überabtastung mit ADASYN (funktionierte nicht so gut wie normales Oversampling)
Vorverarbeitung
Der Datensatz wurde wie folgt vorverarbeitet:
- Alle kategorialen Merkmale wurden in binäre Merkmale umgewandelt.
- Die numerischen Werte wurden normalisiert. Sowohl die Max-Min- als auch die Mean-Std-Normalisierung wurden getestet.
- Daten auf Haushalts- und Einzelebene wurden zusammengeführt (Daten auf individueller Ebene enthielten separate Daten für jedes Mitglied aller Haushalte). Für Attribute, die in Personen- und Haushaltsdaten häufig vorkommen, wurden nur Daten auf Haushaltsebene gespeichert. Allen numerischen Merkmalen im Haushalt wurde ein Mittelwert von (was vielleicht nicht die beste Methode war) zugrunde gelegt, und alle kategorialen Werte wurden zum ungeraden Wert innerhalb des Haushalts aggregiert (wenn das Merkmal X beispielsweise im Haushalt den Wert 1,1,1,0 hatte, würden wir den kombinierten Wert für den Haushalt als 0 annehmen). Der Grund dafür ist, dass viele kategoriale Variablen den Standardwert haben und wir erwartet hatten, dass der ungerade Wert mehr Informationen enthalten würde.
Ansätze, die wir ausprobiert haben
Wir sprechen jetzt über mehrere Ansätze, die wir ausprobiert haben.
- Zuerst sprechen wir über Dinge, die nicht funktioniert haben:
- Wir dachten, dass die Standardattribute für kategoriale Felder für die Modellierung möglicherweise nicht nützlich sind. Um dies zu überprüfen, haben wir Modelle für maschinelles Lernen sowohl mit als auch ohne die Standardattribute trainiert. Modelle, die nicht mit Standardattributen versorgt wurden, schnitten durchweg schlechter ab als Modelle, denen die Standardwerte zugewiesen wurden.
- SMOTE- und ADASYN-Überabtastung lieferte keine besseren Ergebnisse als normales Überabtasten.
- Zweistufiges maschinelles Lernen: In der ersten Phase wird ein Entscheidungsbaum erstellt, um die Wichtigkeit von Funktionen zu ermitteln, und in der anderen Phase werden die wichtigsten Funktionen trainiert. Wir haben durch das Ausprobieren dieser Technik keine Vorteile erzielt.
- Das Ausprobieren verschiedener Methoden zur Normalisierung numerischer Daten änderte nichts an der Genauigkeit. Nicht normalisierte numerische Attribute wiesen jedoch eine schlechtere Genauigkeit auf.
- Die Tricks, die uns geholfen haben, unsere Punktzahl zu erhöhen:
- Die Kombination von numerischen und kategorialen Merkmalen funktionierte beim Trainieren von Algorithmen besser als alle kategorialen Attribute. Zumindest für Entscheidungsbäume.
- Die Wahl der Standardwerte für fehlende Daten hat uns geholfen, unsere Genauigkeit zu verbessern. Wir haben damit begonnen, alle fehlenden Werte auf Null zu setzen, aber später haben wir -999 verwendet, was besser funktionierte.
- Durch die Grid-Suche mit Hyperparametern für maschinelles Lernen konnten wir das Validierungssatz mühelos um 2-4% verbessern.
- Eine starke AutoML-Basislinie hilft uns dabei, gut anzufangen.
- Die Tricks, die wir ausprobieren wollten, aber nicht zu faul zum Programmieren konnten/wollten/waren:
- Feature-Engineering, indem ein kartesisches Produkt nicht standardmäßiger kategorialer Werte genommen und dann wichtige Merkmale ausgewählt werden, mit denen das Modell trainiert werden soll.
- Feature-Engineering, indem numerische Merkmale auf unterschiedliche Weise kombiniert und die Merkmalsauswahl für generierte Features vorgenommen wird.
- Ich probiere Ensembles aus mehreren Modellen aus. Wir hatten uns zuvor das Ziel gesetzt, ein gutes Modell zu bekommen, aber am Ende haben wir trotzdem viele Methoden trainiert. Wir hätten sie wie Stacking zu einem Ensemble kombinieren können.
Algorithmen für maschinelles Lernen



Von uns verwendete Bibliotheken: SKLearn, XGBOOST und TPOT
Wir werden jetzt über maschinelle Lernansätze sprechen, die wir ausprobiert haben. Wir sprechen über Dinge in chronologischer Reihenfolge, also in welcher Reihenfolge wir die Ansätze ausprobiert haben. Bitte beachte, dass alle Tricks, die für uns funktioniert haben, seit unserem ersten Versuch nicht mehr da waren und wir sie nacheinander aufgenommen haben. Bitte sieh dir die Punkte für jeden Versuch an, um zu verstehen, was zu diesem Zeitpunkt in der Pipeline war. Alle verwendeten Modelle für maschinelles Lernen stammten von Scikit Learn-Bibliothek sofern nicht anders angegeben.
- Die üblichen Verdächtigen mit Standardparametern
- Wir haben damit begonnen, die üblichen Verdächtigen mit Standardparametern auszuprobieren. Logistische Regression, SVM und Random Forests. Wir haben auch eine neue Bibliothek namens CATBOOST ausprobiert, aber wir konnten nicht viel Dokumentation über ihre Hyperparameter finden und konnten sie auch nicht gut an Daten anpassen, also haben wir beschlossen, sie durch das bekanntere XGBOOST zu ersetzen. Wir hatten auch Wissen über das XGBOOST-Hyperparameter-Tuning (von dem wir wussten, dass wir es in späteren Phasen tun mussten).
- Beim ersten Versuch wurden alle Spalten als kategoriale Daten und als unausgeglichener Datensatz modelliert.
- Alle Modelle passen gut und bieten uns eine viel bessere Genauigkeit als das Werfen von Münzen bei den Validierungsdaten. Das sagt uns quasi, dass die Datenextraktionspipeline in Ordnung ist (sie hat keine offensichtlichen Fehler, muss aber weiter verfeinert werden).
- Wie die von Wettbewerbsanbietern bereitgestellten Ausgangswerte zeigen Random Forests und XGBOOST mit Standard-Hyperparametern gute Ergebnisse.
- LR und SVM können die Daten gut modellieren (nicht so gut wie RF und XGBOOST aufgrund der geringeren Varianz der Standard-Hyperparameter). SVM (SKLearn SVC) hatte auch eine gute Genauigkeit, aber die Wahrscheinlichkeiten, die es zurückgibt, sind in SkLearn nicht wirklich brauchbar (was meiner Meinung nach ein häufiges Problem mit der Standardeinstellung ist Hyperparameter), was uns veranlasste, SVM fallen zu lassen, da die Konkurrenz nach mittlerem Logloss urteilte. Dies würde zusätzliche Anstrengungen erfordern, um sicherzustellen, dass die Wahrscheinlichkeitszahlen stimmen. Es ist nur so, dass die Wahrscheinlichkeiten, die SVC zurückgibt, nicht gerade eine Wahrscheinlichkeit sind, sondern eine Art von Punktzahl.
- TPOT: AutoML ist eine gute Ausgangsbasis
- Wir fuhren weiterhin damit fort, dass alle Funktionen als kategorisch betrachtet wurden, und versuchten, mithilfe einer AutoML-Methode namens eine Basislinie anzupassen TOPF.
- TPOT verwendet genetische Algorithmen, um eine gute Machine Learning-Pipeline für das jeweilige Problem zu finden und welche Hyperparameter dafür verwendet werden sollen.
- Das brachte uns zum Zeitpunkt der Einreichung in die Top 100 der öffentlichen Bestenliste des Wettbewerbs.
- TPOT benötigt Zeit, um die Pipeline herauszufinden und in wenigen Stunden für den gesamten Datensatz konvergiert zu werden.
- Können neuronale Netze verwendet werden? Irgendjemand neuronale Netze?
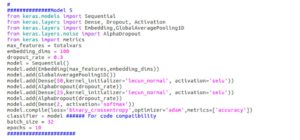
Die Liebe, die wir für Deep Learning haben, hat uns die Hände gejuckt, etwas auszuprobieren, das an neuronale Netzwerke erinnert. Wir machten uns daran, einen guten Algorithmus für neuronale Netzwerke zu trainieren, der auch dieses Problem lösen könnte. Bitte beachten Sie, dass wir zu diesem Zeitpunkt Experimente durchgeführt haben, bei denen alle Spalten als kategorisch betrachtet wurden. Was ist ein Problem, das viele kategoriale Variablen hat und für das eine Bezeichnung vorhergesagt werden muss? Textklassifizierung. Das ist ein Ort, an dem neuronale Netze sehr glänzen. Im Gegensatz zu Text hat dieser Datensatz jedoch kein Sequenzkonzept. Deshalb haben wir uns für ein neuronales Netzwerk entschieden, das bei der Textklassifizierung üblich ist, aber die Reihenfolge nicht berücksichtigt. Dieser Algorithmus ist Schneller Text. Wir haben eine (tiefe) Version von Schnelltext wie dem Algorithmus in Keras geschrieben, um mit dem Datensatz zu trainieren. Eine weitere Maßnahme, die wir zum Training von Neural Network unternommen haben, war die Überabtastung einer Minderheitenklasse, da diese bei unausgeglichenen Daten nicht gut trainierte.
[caption id="attachment_3089" align="alignnone“ width="727"]
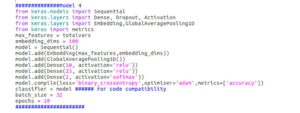
FFNN verwendet [/caption]
Wir haben versucht, mit den kürzlich vorgeschlagenen selbstnormalisierten neuronalen Netzwerken zu trainieren. Dies gab uns eine kostenlose Erhöhung der Genauigkeit des Validierungssatzes.
[caption id="attachment_3090" align="alignnone“ width="746"]
Self Normalized FFNN (SELU) haben wir verwendet [/caption]
Obwohl wir beim Validierungssatz an Genauigkeit gewinnen, wenn wir Deep Neural Networks verwenden, insb. Land B, in dem die höchste Genauigkeit, die wir je erhalten haben (sogar besser als unser leistungsstärkstes Modell), die Verwendung von Self Normalized Deep Neural Network war, werden die Ergebnisse nicht auf der Bestenliste übertragen, wo wir immer wieder niedrige Punktzahlen erzielen (hoher Logloss).
- Auf dem Weg zur Verbesserung der AutoML Baseline und zur Optimierung von XGBOOST
Die von uns erstellte AutoML-Baseline starrte uns immer noch ins Gesicht, da all unsere handgefertigten Methoden immer noch schlechter waren. Wir haben uns daher entschlossen, auf die bewährten XGBOOST-Modelle umzusteigen, um die Ergebnisse zu verbessern. Wir haben eine Datenpipeline geschrieben, um verschiedene Tricks auszuprobieren, die wir zu Beginn des Segments erwähnt haben (erfolgreich/erfolglos), und eine Pipeline zu Grid Search über verschiedene Hyperparameter und eine 5-fache Cross-Validation.
[caption id="attachment_3091" align="alignnone“ width="739"]

Beispiel für eine Rastersuche für den einzelnen Validierungssatz [/caption]
Die oben genannten Tricks in Kombination mit der Grid-Suche haben unsere Punktzahlen massiv verbessert und wir konnten den Wert von 0,2 Logloss und dann auch 0,9 Logloss übertreffen. Wir haben ein weiteres TPOT-AutoML mit einem Datensatz ausprobiert, der durch unsere erfolgreichen Tricks generiert wurde, aber es konnte nur bis zu einer Pipeline mit fast 0,2 Logloss auf der Bestenliste mithalten. Letztlich erwies sich das XGBOOST-Modell also als das beste. Wir konnten die Genauigkeit derselben Reihenfolge nicht erreichen, als wir versuchten, die Grid-Suche über Parameter eines Random-Forest-Algorithmus durchzuführen.
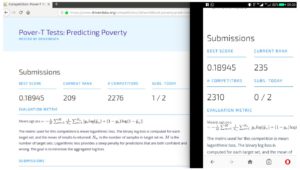
Unser Punkte/Rang hat sich auf der privaten Bestenliste etwas verschlechtert als auf der Bestenliste der öffentlichen Wettbewerbe. Wir haben den Wettbewerb bei etwa 90 Perzentil beendet.
Wir hoffen, dir hat der Artikel gefallen. Bitte Melde dich an für ein kostenloses Komprehend-Konto, um Ihre KI-Reise zu beginnen. Sie können sich auch Demos der Komprehend KI-APIs ansehen hier.


.png)