Share it with your network.
La digitalización ha cambiado la forma en que procesamos y analizamos la información. Hay un aumento exponencial en la disponibilidad de información en línea. Desde páginas web hasta correos electrónicos, las revistas científicas, los libros electrónicos, el contenido de aprendizaje, las noticias y las redes sociales están repletos de datos textuales. La idea es crear, analizar y reportar información rápidamente. Aquí es cuando se intensifica la clasificación automática de textos.
La clasificación de texto es una clasificación inteligente del texto en categorías. Además, el uso del aprendizaje automático para automatizar estas tareas hace que todo el proceso sea muy rápido y eficiente. La inteligencia artificial y el aprendizaje automático son sin duda las tecnologías más beneficiosas que han cobrado impulso en los últimos tiempos. Están encontrando aplicaciones en todas partes. Como dijo Jeff Bezos en su carta anual a los accionistas:
Durante las últimas décadas, las computadoras han automatizado ampliamente las tareas que los programadores podían describir con reglas y algoritmos claros. Las técnicas modernas de aprendizaje automático ahora nos permiten hacer lo mismo en tareas en las que es mucho más difícil describir las reglas precisas.
- Jeff Bezos
Hablando particularmente sobre la clasificación automática de textos, ya hemos escrito sobre la tecnología detrás de ella y sus aplicaciones. Ahora estamos actualizando nuestro clasificador de texto. En esta publicación, hablamos sobre la tecnología, las aplicaciones, la personalización y la segmentación relacionadas con nuestra clasificación automática de textos API.
El análisis de intención, emoción y sentimiento de los datos textuales es una de las partes más importantes de la clasificación de textos. Estos casos de uso han despertado una gran expectación entre los entusiastas de la inteligencia artificial. Hemos desarrollado clasificadores separados para cada una de estas categorías, ya que su estudio es un tema enorme en sí mismo. El clasificador de texto puede funcionar en una variedad de conjuntos de datos textuales. Puede entrenar el clasificador con datos etiquetados u operar también con texto sin procesar sin estructura. Ambas categorías tienen numerosas aplicaciones por sí mismas.
Clasificación supervisada de textos
La clasificación supervisada del texto se realiza cuando se han definido las categorías de clasificación. Funciona según el principio de entrenamiento y prueba. Introducimos datos etiquetados al algoritmo de aprendizaje automático para que trabaje en ellos. El algoritmo se entrena en el conjunto de datos etiquetado y proporciona el resultado deseado (las categorías predefinidas). Durante la fase de prueba, el algoritmo se alimenta de datos no observados y los clasifica en categorías según la fase de entrenamiento.
El filtrado de correos electrónicos no deseados es un ejemplo de clasificación supervisada. El correo electrónico entrante se clasifica automáticamente en función de su contenido. La detección del lenguaje y el análisis de intenciones, emociones y sentimientos se basan todos en sistemas supervisados. Puede funcionar para casos de uso especiales, como la identificación de situaciones de emergencia mediante el análisis de millones de información en línea. Es una aguja en el problema del pajar. Propusimos un sistema de transporte público inteligente para identificar este tipo de situaciones. Para identificar una situación de emergencia entre millones de conversaciones en línea, el clasificador debe estar entrenado con alta precisión. Para resolver este problema, necesita funciones especiales de pérdida, la toma de muestras durante el entrenamiento y métodos como crear una pila de varios clasificadores, cada uno de los cuales refina los resultados del anterior.
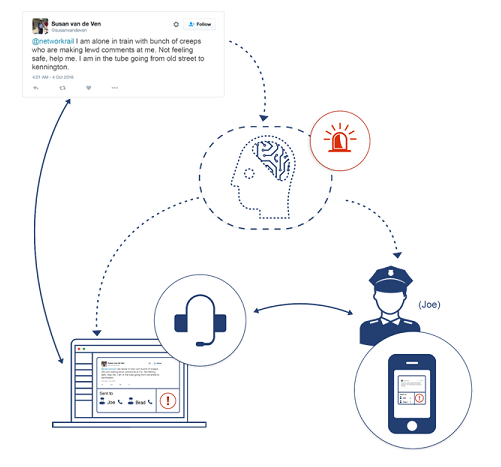
La clasificación supervisada consiste básicamente en pedir a las computadoras que imiten a los humanos. Los algoritmos reciben un conjunto de texto etiquetado o categorizado (también denominado conjunto de trenes) a partir del cual generan modelos de IA. Estos modelos, cuando reciben más texto nuevo sin etiquetar, pueden clasificarlos automáticamente. Varios de nuestros APIs, se desarrollan con sistemas supervisados. Los clasificador de texto está actualmente capacitado para un conjunto de 150 categorías genéricas.
Clasificación de texto sin supervisión
La clasificación no supervisada se realiza sin proporcionar información externa. Aquí los algoritmos intentan descubrir la estructura natural de los datos. Tenga en cuenta que la estructura natural puede no ser exactamente lo que los humanos consideran una división lógica. El algoritmo busca patrones y estructuras similares en los puntos de datos y los agrupa en clústeres. La clasificación de los datos se realiza en función de los clústeres formados. Tomemos como ejemplo la búsqueda en la web. El algoritmo crea clústeres en función del término de búsqueda y los presenta como resultados al usuario.
Todos los puntos de datos están incrustados en el hiperespacio y puedes visualizarlos en TensorBoard. La siguiente imagen se basa en un estudio de Twitter que hicimos sobre Reliance Jio, una empresa de telecomunicaciones india.

La exploración de datos se realiza para encontrar puntos de datos similares en función de la similitud textual. Estos puntos de datos similares corresponden a un grupo de vecinos más cercanos. La imagen de abajo muestra a los vecinos más cercanos del tuit «Membresía prime de Reliance Jio por 99 rupias: aquí se explica cómo obtener un reembolso de 100 rupias...».

Como puedes ver, los tuits que los acompañan son similares a los tuits etiquetados. Este grupo es una categoría de tuits similares. La clasificación sin supervisión resulta útil a la hora de generar información a partir de datos textuales. Es altamente personalizable, ya que no es necesario etiquetar. Puede funcionar con cualquier dato textual sin necesidad de entrenarlo ni etiquetarlo. Por lo tanto, la clasificación no supervisada es independiente del idioma.
Clasificación de texto personalizada
Muchas veces, el mayor obstáculo para usar el aprendizaje automático es la falta de disponibilidad de un conjunto de datos. Hay muchas personas que quieren usar la inteligencia artificial para categorizar los datos, pero necesitan crear un conjunto de datos, lo que genera una situación similar a la del problema del huevo de gallina. La clasificación de texto personalizada es una de las mejores maneras de crear su propio clasificador de texto sin ningún conjunto de datos.
En el último trabajo de investigación de ParallelDots, hemos propuesto un método para aprender desde cero en el texto, mediante el cual se puede crear un algoritmo entrenado para aprender las relaciones entre las oraciones y sus categorías en un conjunto de datos grande y ruidoso para generalizarlo a nuevas categorías o incluso a nuevos conjuntos de datos. A este paradigma lo denominamos «Entrena una vez, prueba en cualquier lugar». También proponemos múltiples algoritmos de redes neuronales que pueden aprovechar esta metodología de entrenamiento y obtener buenos resultados en diferentes conjuntos de datos. El mejor método utiliza un modelo LSTM para la tarea de aprender las relaciones. La idea es que si se puede modelar el concepto de «pertenencia» entre oraciones y clases, el conocimiento es útil para las clases invisibles o incluso para los conjuntos de datos invisibles.
¿Cómo crear un clasificador de texto personalizado?
Para crear su propio clasificador de texto personalizado, primero debe regístrate para una cuenta ParallelDots y iniciar sesión a tu panel de control.
Consulta el muestra para probar nuestro clasificador personalizado.
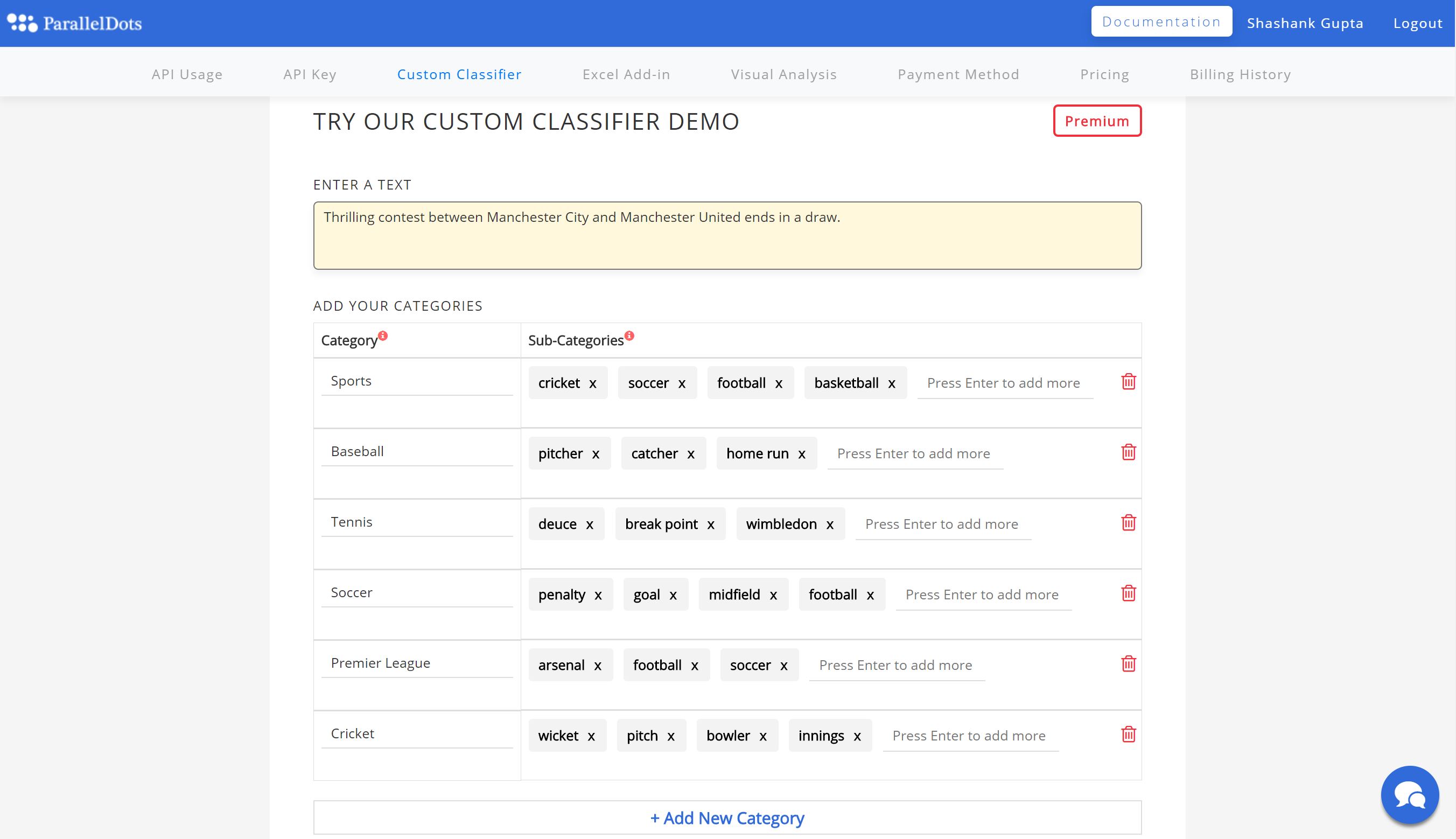
Puedes comprobar la precisión de la clasificación analizando una muestra de tu texto y modificar tu lista de categorías tanto como quieras antes de publicarlas. Una vez que se publiquen las categorías, obtendrás un identificador de aplicación que te permitirá usar la API de clasificación personalizada.
Teniendo en cuenta que el etiquetado y la preparación de datos pueden ser una limitación, Custom Classifier puede ser una gran herramienta para crear un clasificador de texto sin mucha inversión. También creemos que reducirá el umbral de la creación de modelos prácticos de aprendizaje automático que puedan aplicarse en todos los sectores y resolver una variedad de casos de uso.
Como grupo de investigación de IA, desarrollamos constantemente tecnologías de vanguardia para simplificar y acelerar los procesos. La clasificación de textos es una de esas tecnologías que tiene un enorme potencial en el futuro próximo. A medida que se descarga más y más información en Internet, depende de los algoritmos de las máquinas inteligentes facilitar el análisis y la representación de esta información. El futuro de la inteligencia artificial es sin duda emocionante. Suscríbase a nuestro boletín para recibir más información de este tipo en su bandeja de entrada.
Esperamos que os haya gustado el artículo. Por favor Inscríbase para obtener una cuenta Komprehend gratuita para comenzar su viaje con la IA. También puedes consultar las demostraciones de las API de IA de Komprehend aquí.


.png)