Share it with your network.
Reconhecimento de entidade nomeada (NER) é um ramo particularmente interessante da Processamento de linguagem natural (PNL) e uma subparte da Recuperação da Informação (IR). Um modelo NER é treinado para extrair e classificar determinadas ocorrências em um trecho de texto em categorias predefinidas. Quais são essas categorias? Que bom que você perguntou. As categorias podem ser consideradas como o tipo de entidades que um modelo NER pode extrair. Por exemplo, pode ser um nome (de uma organização, uma pessoa, um lugar...), parâmetros de medição, porcentagens, etc.

Compreendido tem um nível industrial PERTO DE API que funciona no idioma inglês. No entanto, o mundo é um lugar diverso e o idioma inglês nem sempre é suficiente. Tendo isso em mente, adicionamos recentemente a capacidade de extração multilíngue ao nosso modelo NER atual. Esta postagem discutirá esse novo recurso. Também analisaremos detalhadamente a aplicação e os usos do Named Entity Recognition.
Como funciona um modelo de reconhecimento de entidades nomeadas?
A imagem abaixo dá uma ideia do método empregado para realizar o reconhecimento de entidades nomeadas.
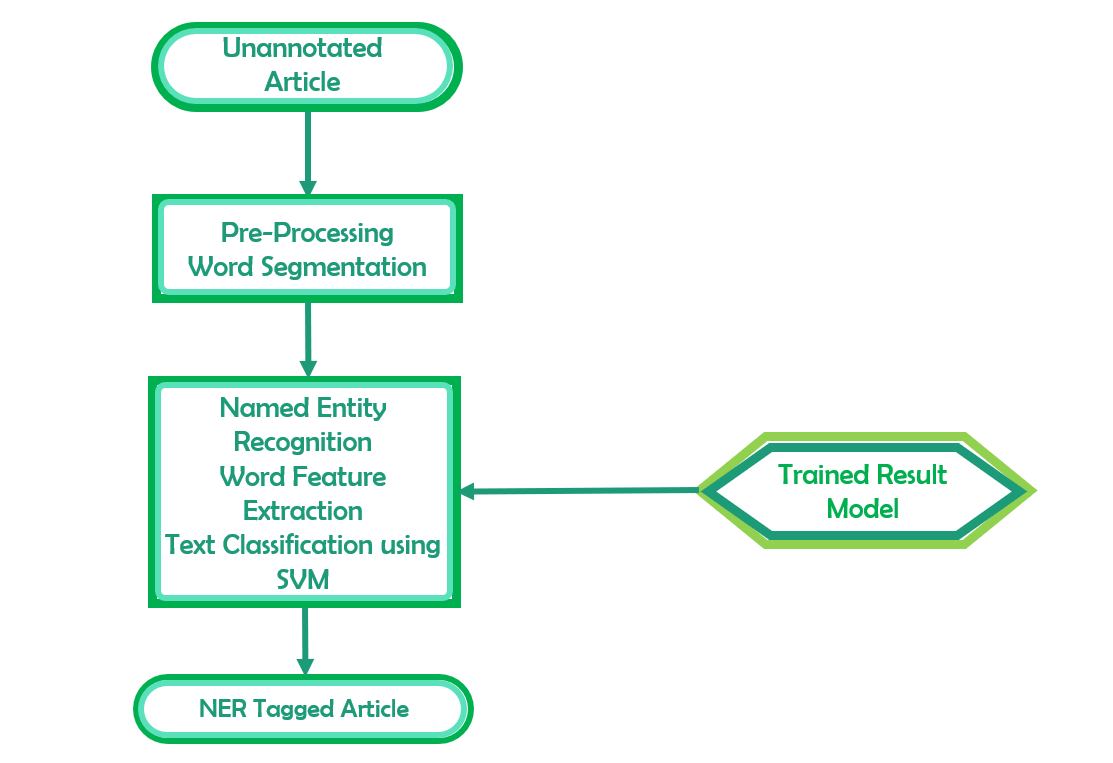
Nossa API usa tecnologia de aprendizado profundo. Abaixo, você encontra uma breve descrição da nossa tecnologia:
- Os Word Embeddings são treinados em um enorme corpus de texto que nossa extensa infraestrutura de rastreamento coleta da web aberta. Essas incorporações são treinadas usando o algoritmo GLOve ou Word2Vec. Usamos incorporações GoVe na produção. Esse algoritmo converte cada palavra em um vetor denso de 100 dimensões. A rede neural que treinamos usa esses Embeddings como entradas em vez de palavras diretamente.
- Nossa equipe interna de marcação de dados anotou um enorme conjunto de entidades presentes nos dados que rastreamos. Por exemplo, a frase “Esta é uma casa que Jack construiu” é anotada com (Jack, Pessoa) e “Ram e Shyam estão indo para Delhi” é anotada com (Ram, Pessoa), (Shyam, Pessoa) e (Delhi, Lugar). Nosso conjunto de dados interno tem mais de 200.000 dessas frases anotadas.
- Em seguida, treinamos uma sequência de rotulagem LSTM bidirecional em cima do conjunto de dados marcado mencionado acima para prever se cada palavra em uma frase é uma entidade ou não. Uma LSTM ou Long Short Memory Network é uma RNN melhor, que evita o amortecimento de gradiente ao converter o paradigma de multiplicação da recorrência geral em um paradigma de adição.
- A camada de atenção também foi testada no LSTM para ver se ela pode ajudar a identificar propriedades importantes em uma frase que define uma palavra como uma entidade. Ainda estamos refinando o modelo com atenção e o modelo em produção é LSTM sem atenção.
Do total de dados fornecidos como entrada, 10% foram usados para testar o sistema e o restante para treiná-lo. Nosso modelo de rede neural atinge uma pontuação F1 de 92,8 quando treinado no conjunto de dados Conll-03.
API multilíngue de reconhecimento de entidades nomeadas em ação
Depois dos detalhes da nossa arquitetura, vamos ver a API em ação. Você também pode testar nosso modelo a partir de um demonstração gratuita hospedada aqui.

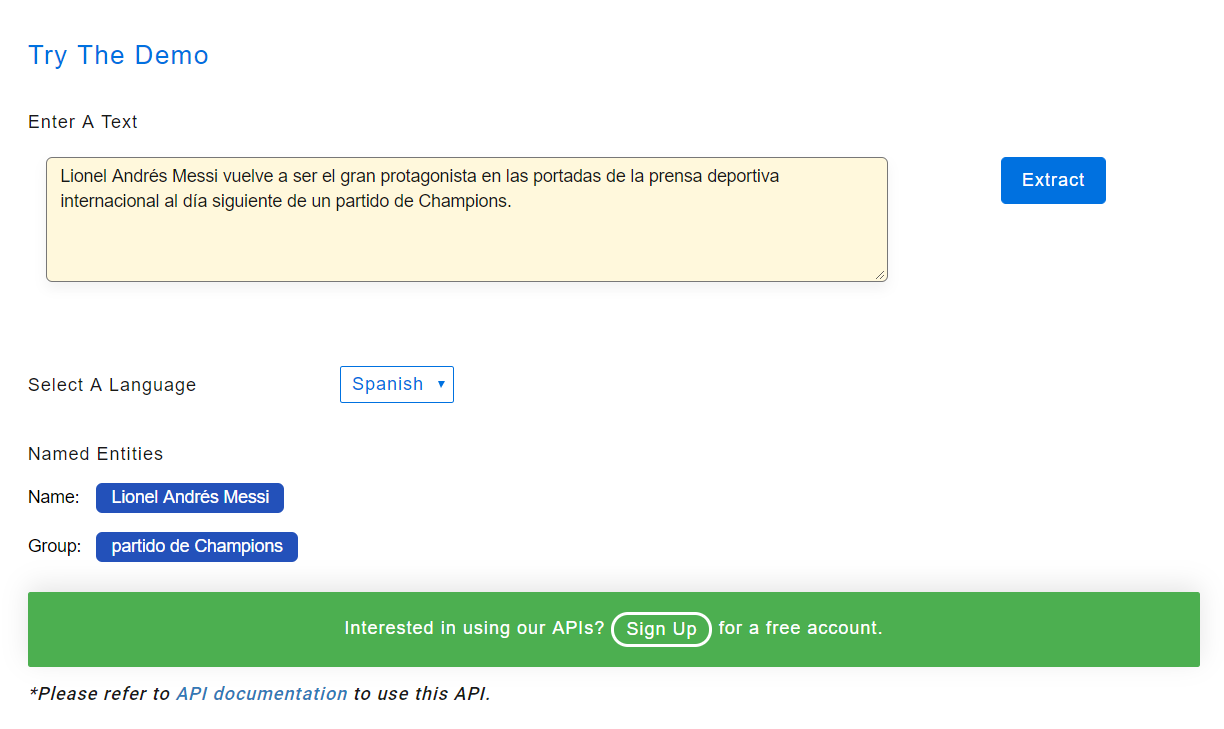
Reconhecimento de entidade nomeada - espanhol
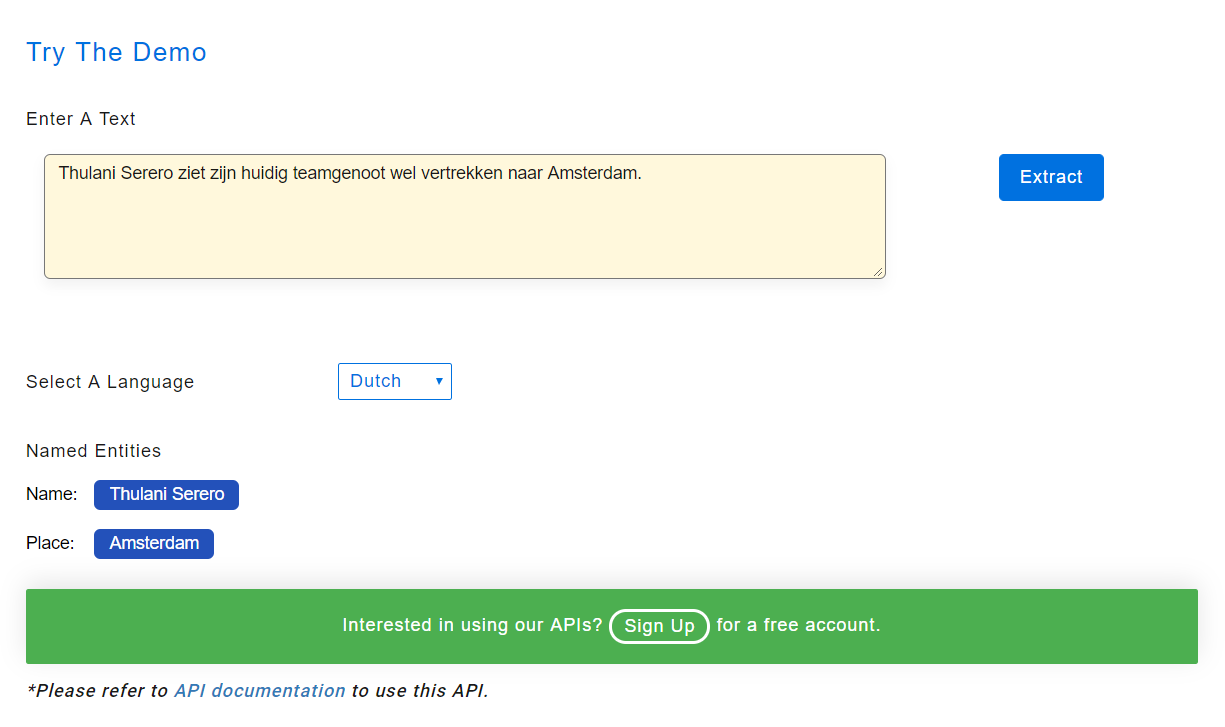
Reconhecimento de entidade nomeada - holandês
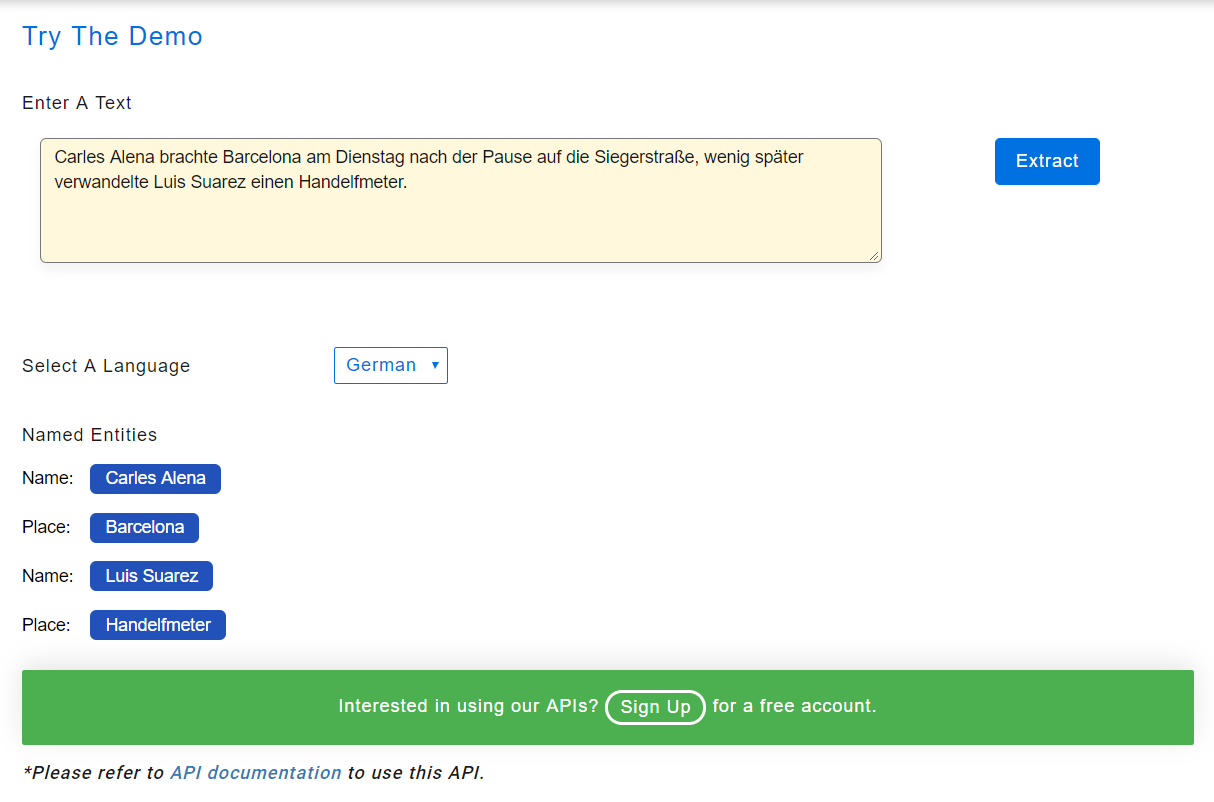
Reconhecimento de entidade nomeada - alemão
Aplicações industriais do NER
Nossa API NER é verdadeiramente independente do setor, com uma ampla variedade de aplicações. Vamos dar uma olhada em alguns deles.
#1 Sistema de extração de informações
O reconhecimento de entidades nomeadas é uma subparte dos sistemas de recuperação de informações. Entidades nomeadas carregam informações importantes sobre os dados textuais que estão sendo analisados. Se um sistema for desenvolvido para extrair entidades nomeadas de um documento, a precisão do sistema de extração de informações pode ser aumentada várias vezes.
O reconhecimento de entidades nomeadas é a compensação de muitas tarefas importantes de recuperação de informações. Por exemplo, tarefas de extração de informações biomédicas, extração de eventos, sistemas de extração de relações, etc., começam com o reconhecimento de entidades nomeadas.
#2 Sistemas de tradução automática
A linguística computacional é um campo de estudo que trata da aplicação de técnicas da ciência da computação para realizar análises e sínteses linguísticas. Uma subparte da linguística computacional é a tradução automática ou a conversão de fala ou texto de um idioma natural para outro.
Quando se trata de tradução automática, entidades nomeadas se mostram especialmente complicadas porque sua tradução é baseada em regras específicas do idioma. Se as entidades nomeadas forem extraídas antes da tradução real, todo o processo se tornará muito mais preciso.
#3 Anotação semântica eficiente
A anotação semântica é o processo de adicionar informações a um documento. Essas informações adicionadas geralmente são chamadas de entidades que podem ajudar as máquinas a entender as nuances de um documento textual. As anotações semânticas têm como objetivo enriquecer documentos não estruturados ou semiestruturados com relações estruturadas adaptadas ao domínio.
Os sistemas NER podem extrair essas anotações e relações, aumentando a eficiência da análise acionada por máquina. Essa automação é realizada usando sistemas NER, que são empregados para identificar conceitos e relações que valem a pena anotar.
O reconhecimento de entidades nomeadas tem muitos usos diversos, além dos mencionados acima. Por exemplo, os sistemas NER foram usados para resolver problemas complexos relacionados ao agrupamento de texto, mineração de opiniões, etc. Em uma edição anterior publicar, discutimos as aplicações e os casos de uso dos sistemas de reconhecimento de entidades nomeadas com muito mais detalhes.
Esperamos que você tenha gostado do artigo. Por favor Cadastre-se para obter uma conta gratuita do Komprehend para começar sua jornada de IA agora. Você também pode conferir demonstrações gratuitas das APIs Komprehend AI aqui.
.png)
.png)
.png)