Share it with your network.
Erkennung benannter Entitäten (NER) ist ein besonders interessanter Zweig von Verarbeitung natürlicher Sprache (NLP) und ein Unterabschnitt von Information Retrieval (IR). Ein NER-Modell ist darauf trainiert, bestimmte Vorkommen in einem Text zu extrahieren und in vordefinierte Kategorien zu klassifizieren. Was sind diese Kategorien? schön, dass du gefragt hast. Die Kategorien können als die Art von Entitäten betrachtet werden, die ein NER-Modell extrahieren kann. Es kann sich beispielsweise um einen Namen (einer Organisation, einer Person, eines Ortes...), Messparameter, Prozentsätze usw. handeln.

Verstehen hat eine Industriequalität NAHE CAPI was in der englischen Sprache funktioniert. Die Welt ist jedoch vielfältig und die englische Sprache reicht nicht immer aus. Vor diesem Hintergrund haben wir kürzlich unser aktuelles NER-Modell um mehrsprachige Extraktionsfunktionen erweitert. In diesem Beitrag wird diese neue Funktion erörtert. Wir werden uns auch eingehend mit der Anwendung und Verwendung von Named Entity Recognition befassen.
Wie funktioniert ein Named Entity Recognition-Modell?
Das Bild unten gibt einen Einblick in die Methode, mit der die Erkennung benannter Entitäten durchgeführt wird.
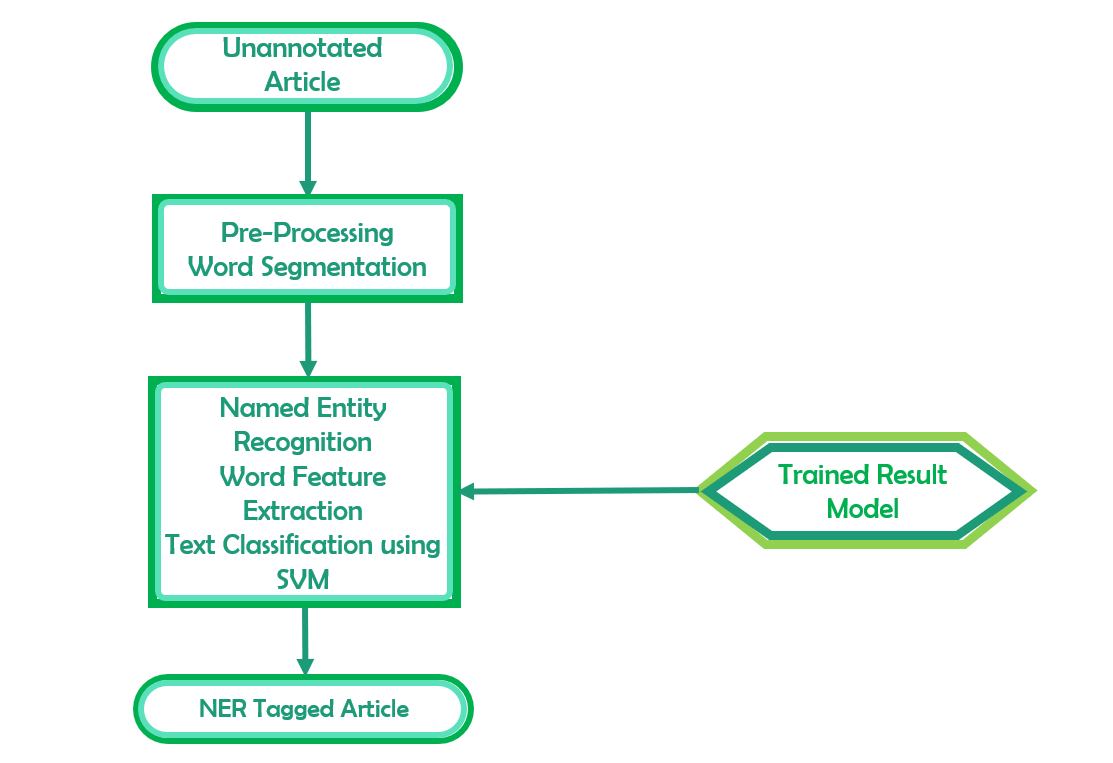
Unsere API verwendet Deep-Learning-Technologie. Im Folgenden finden Sie eine kurze Beschreibung unserer Technologie:
- Worteinbettungen werden auf einem riesigen Textkorpus trainiert, den unsere umfangreiche Crawling-Infrastruktur aus dem offenen Web sammelt. Diese Einbettungen werden entweder mit dem GloVE- oder dem Word2Vec-Algorithmus trainiert. Wir verwenden GloVE-Einbettungen in der Produktion. Dieser Algorithmus wandelt jedes Wort in einen dichten 100-dimensionalen Vektor um. Das neuronale Netzwerk, das wir trainieren, verwendet diese Einbettungen als Eingaben und nicht als direkte Wörter.
- Unser internes Datentagging-Team kommentierte einen riesigen Datensatz von Entitäten, die in den von uns gecrawlten Daten enthalten sind. So ist beispielsweise der Satz „Das ist ein Haus, das Jack gebaut hat“ mit (Jack, Person) und „Ram und Shyam gehen nach Delhi“ mit (Ram, Person), (Shyam, Person) und (Delhi, Ort) annotiert. Unser interner Datensatz enthält über 200.000 solcher kommentierten Sätze.
- Anschließend trainieren wir eine Sequenzkennzeichnung bidirektionales LSTM zusätzlich zu dem oben genannten markierten Datensatz, um vorherzusagen, ob jedes Wort in einem Satz zu einer Entität gehört oder nicht. Ein LSTM oder Long Short Memory Network ist ein besseres RNN, das eine Gradientendämpfung vermeidet, indem es das Multiplikationsparadigma der allgemeinen Wiederholung in ein Additionsparadigma umwandelt.
- Die Aufmerksamkeitsschicht wurde auch in LSTM ausprobiert, um zu sehen, ob sie helfen kann, über wichtige Eigenschaften in einem Satz zu informieren, die ein Wort als Entität definieren. Wir sind immer noch dabei, das Modell mit Aufmerksamkeit zu verfeinern, und das in Produktion befindliche Modell ist LSTM ohne Aufmerksamkeit.
Von den Gesamtdaten, die als Eingabe eingegeben wurden, wurden 10% für das Testen des Systems und die restlichen für das Training verwendet. Unser neuronales Netzwerkmodell erreicht einen F1-Score von 92,8, wenn es mit dem Conll-03-Datensatz trainiert wird.
Mehrsprachige API zur Erkennung benannter Entitäten in Aktion
Schauen wir uns nach den Details unserer Architektur die API in Aktion an. Sie können unser Modell auch von einem aus testen kostenlose Demo hier gehostet.

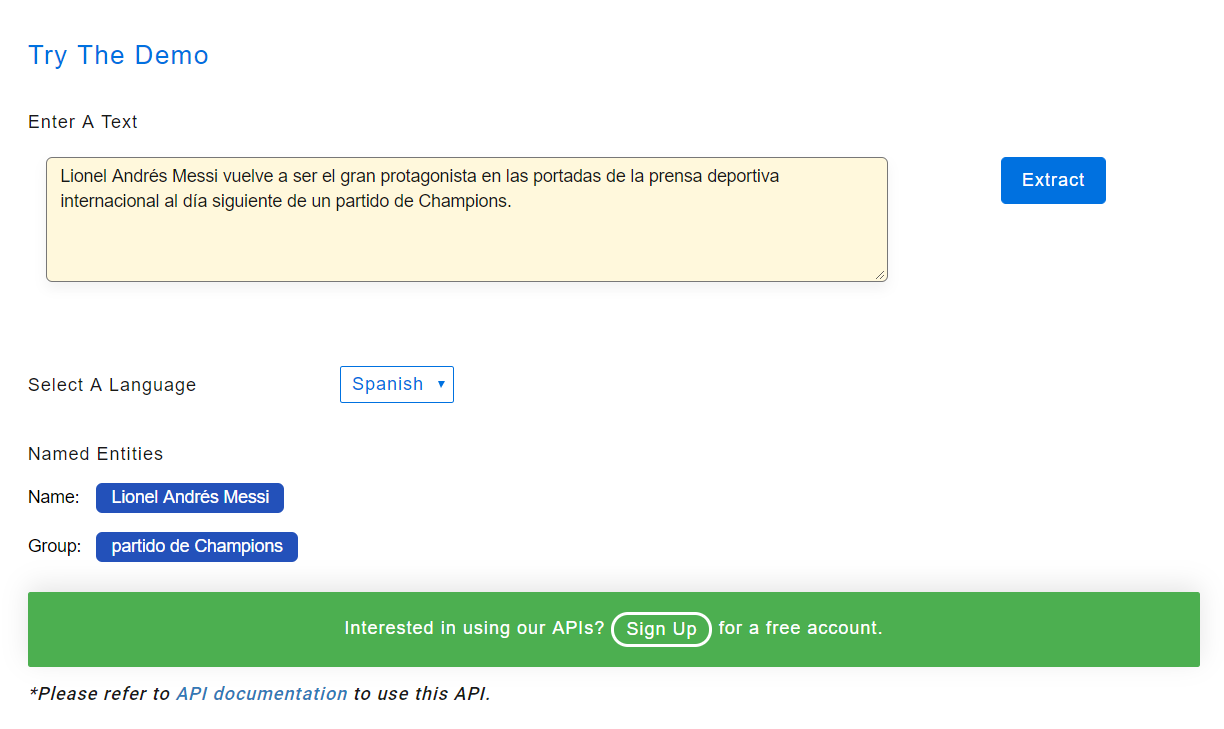
Anerkennung benannter Entitäten — Spanisch
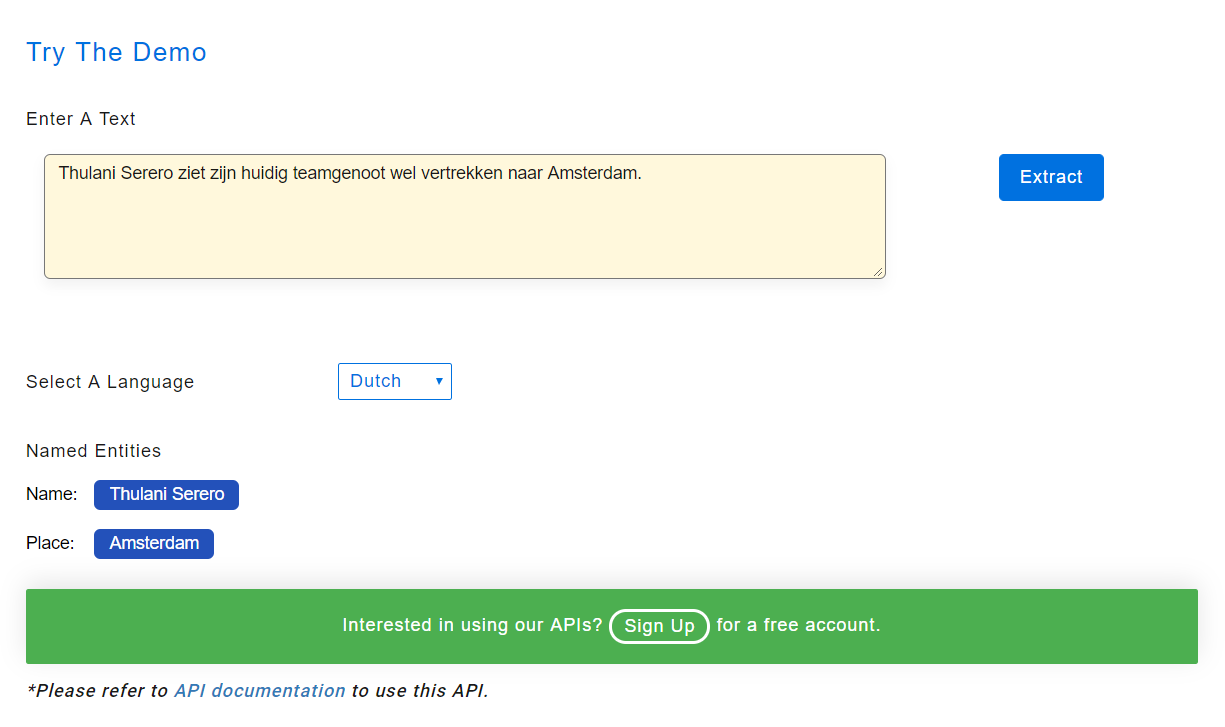
Anerkennung benannter Entitäten — Niederländisch
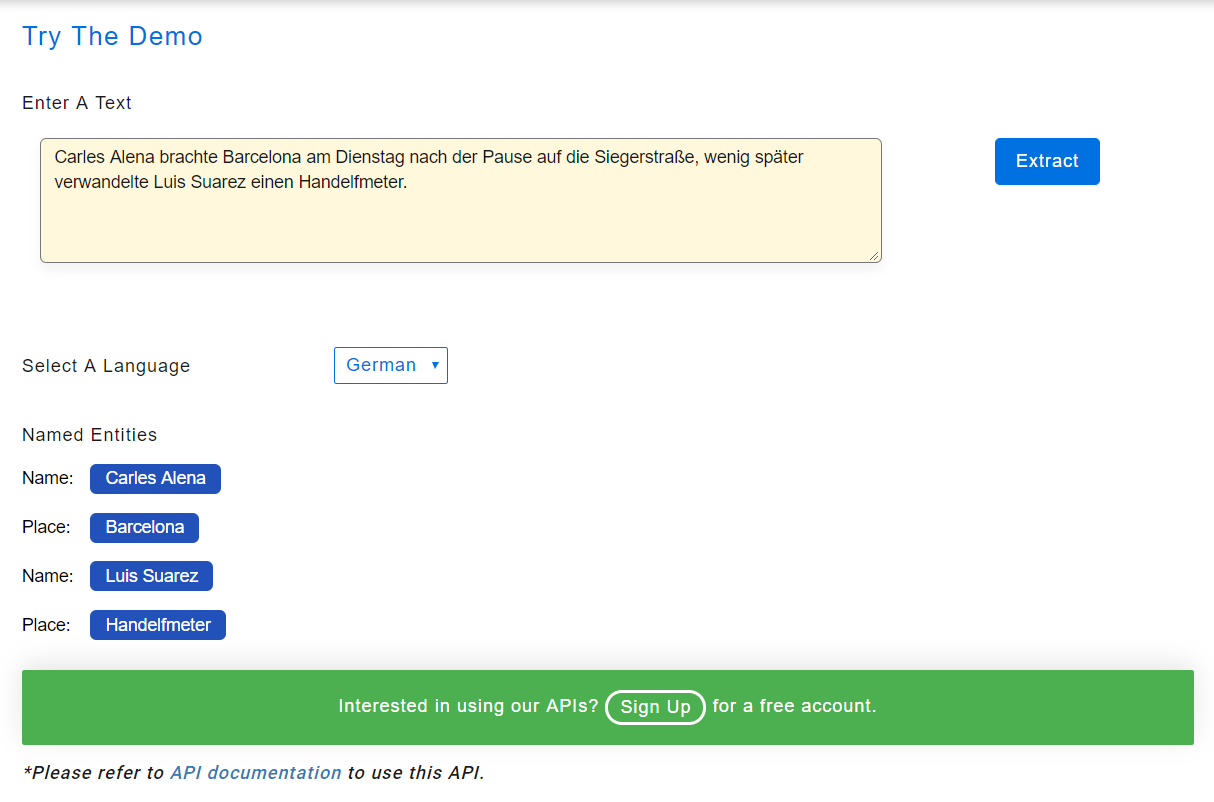
Erkennung benannter Entitäten — Deutsch
Industrielle Anwendungen von NER
Unsere NER-API ist wirklich branchenunabhängig und bietet ein breites Anwendungsspektrum. Schauen wir uns einige davon an.
#1 Informationsextraktionssystem
Named Entity Recognition ist ein Unterabschnitt der Information Retrieval-Systeme. Benannte Entitäten enthalten wichtige Informationen über die zu analysierenden Textdaten. Wenn ein System entwickelt wurde, um benannte Entitäten aus einem Dokument zu extrahieren, kann die Genauigkeit des Informationsextraktionssystems um ein Vielfaches erhöht werden.
Die Erkennung benannter Entitäten ist das Gegengewicht zu vielen wichtigen Aufgaben beim Abrufen von Informationen. So beginnen beispielsweise Aufgaben zur Extraktion biomedizinischer Informationen, zur Extraktion von Ereignissen, zur Extraktion von Beziehungen usw. mit der Erkennung benannter Entitäten.
#2 Systeme für maschinelle Übersetzung
Die Computerlinguistik ist ein Studienfach, das sich mit der Anwendung von Informatiktechniken zur Durchführung sprachlicher Analysen und Synthesen befasst. Ein Teilbereich der Computerlinguistik ist die maschinelle Übersetzung oder Konvertierung von Sprache oder Text von einer natürlichen Sprache in eine andere.
Bei der maschinellen Übersetzung erweisen sich benannte Entitäten als besonders knifflig, da ihre Übersetzung auf sprachspezifischen Regeln basiert. Wenn die benannten Entitäten vor der eigentlichen Übersetzung extrahiert werden, wird der gesamte Prozess viel genauer.
#3 Effiziente semantische Annotation
Semantische Annotation ist der Prozess des Hinzufügens von Informationen zu einem Dokument. Diese zusätzlichen Informationen werden im Allgemeinen als Entitäten bezeichnet, die Maschinen helfen können, die Nuancen eines Textdokuments zu verstehen. Semantische Anmerkungen zielen darauf ab, unstrukturierte oder halbstrukturierte Dokumente mit domänenangepassten strukturierten Beziehungen anzureichern.
NER-Systeme können solche Anmerkungen und Beziehungen extrahieren und so die Effizienz maschineller Analysen erhöhen. Diese Automatisierung erfolgt mithilfe von NER-Systemen, die zur Identifizierung von Konzepten und Beziehungen eingesetzt werden, die es wert sind, kommentiert zu werden.
Named Entity Recognition hat neben den oben genannten viele verschiedene Anwendungen. NER-Systeme wurden beispielsweise zur Lösung komplexer Probleme im Zusammenhang mit Textclustern, Meinungsforschung usw. eingesetzt. In einer früheren Version Post, wir haben die Anwendungen und Anwendungsfälle von Named Entity Recognition-Systemen viel ausführlicher erörtert.
Wir hoffen, dir hat der Artikel gefallen. Bitte Melde dich an für ein kostenloses Komprehend-Konto, um jetzt Ihre KI-Reise zu beginnen. Sie können sich auch kostenlose Demos der Komprehend KI-APIs ansehen hier.


.png)