Share it with your network.
O Large Scale Visual Recognition Challenge (ILSVRC) viu um declínio exponencial nas 5 principais taxas de erro da arquitetura de rede neural para classificação de imagens nos últimos anos
Os modelos de aprendizado profundo para classificação de imagens têm crescido em termos de precisão nos últimos anos. O aprendizado profundo se tornou a principal área de foco da pesquisa de IA. No entanto, o Deep Learning já existe há algumas décadas. Yann Lecun, apresentou um papel pioneira nas Redes Neurais Convolucionais (CNN) em 1998. Mas foi só no início da década atual que o Deep Learning realmente decolou. Em um anterior publicar listamos alguns trabalhos de pesquisa inovadores relacionados a Análise de sentimentos.

Para nós, humanos, é muito fácil entender o conteúdo de uma imagem. Por exemplo, enquanto assisto a um filme (como O Senhor dos Anéis), eu só preciso ver um exemplo de um anão e isso me permite identificar outros anões sem nenhum esforço. No entanto, para uma máquina, a tarefa é extremamente desafiadora porque tudo o que ela pode ver em uma imagem é uma matriz de números. Se a tarefa é identificar um gato em uma imagem, você pode perceber a dificuldade em encontrar um gato nessa grande variedade de números. Além disso, os gatos vêm em todas as formas, tamanhos, cores e poses, tornando a tarefa ainda mais desafiadora.
Artigos de pesquisa inovadores sobre classificação de imagens
AlexNet
No ILSVRC 2012, Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton apresentaram AlexNet, uma CNN profunda. A AlexNet registrou uma taxa de erro de 15,4%, superando a segunda melhor entrada em mais de 10% (A segunda melhor entrada teve a taxa de erro de 26,2%). Esse feito impressionante da AlexNet conquistou toda a comunidade de Visão Computacional e transformou o Deep Learning e as CNNs nas interrupções que são hoje.
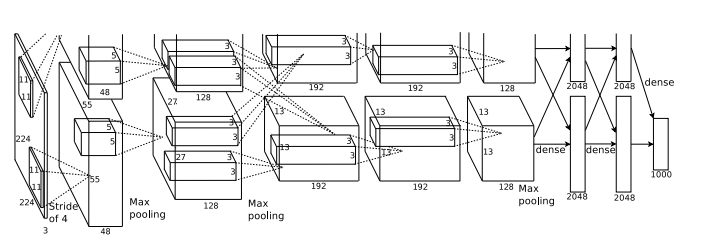
Essa foi a primeira vez que um modelo teve um desempenho tão bom em um conjunto de dados ImageNet historicamente difícil. A AlexNet estabeleceu a base do aprendizado profundo avançado. Ainda é um dos artigos mais citados sobre Deep Learning, sendo citado cerca de 7000 vezes.
ZFnet
Matthew D Zeiler (fundador da Clarifai) e Rob Fergus venceram o ILSVRC em 2013, superando a AlexNet ao reduzir a taxa de erro para 11,2%. O ZFnet introduziu uma nova técnica de visualização que fornece informações sobre a função das camadas intermediárias de recursos e a operação do classificador, ambas ausentes no AlexNet.
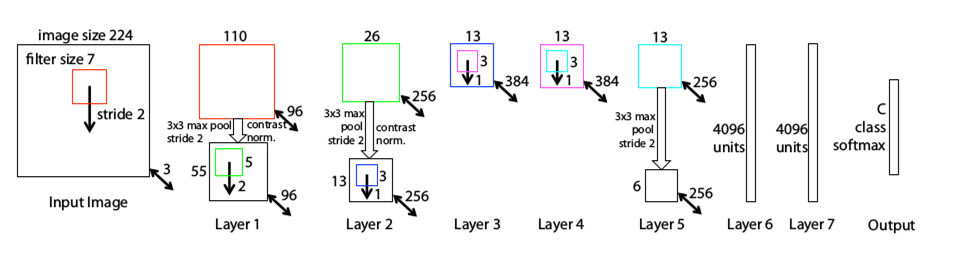
O ZFnet abriu a possibilidade de examinar diferentes ativações de recursos e sua relação com o espaço de entrada usando uma técnica chamada Rede Deconvolucional.
Rede VGG
Karen Simonyan e Andrew Zisserman, da Universidade de Oxford, criaram uma CNN profunda que foi escolhida como a segunda melhor entrada na tarefa de Classificação de Imagens do ISLVRC 2014. O VGG Net mostrou que uma melhoria significativa nas configurações anteriores pode ser alcançada aumentando a profundidade para 16-19 camadas de peso, o que é substancialmente mais profundo do que o que foi usado na técnica anterior.
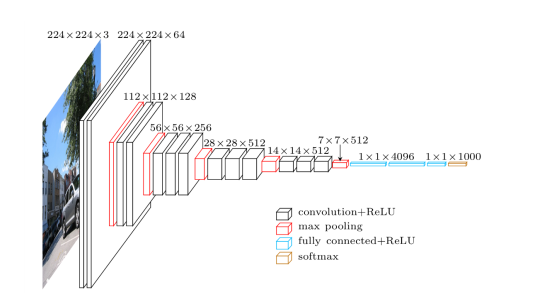
A arquitetura foi elogiada porque era muito mais simples de entender (mais simples do que o GoogleLeNet, vencedor do ISLVRC 2014), mas ainda conseguia gerenciar a precisão ideal. Seus mapas de recursos são muito usados agora em aprendizado de transferência e outros algoritmos que exigem redes pré-treinadas, como a maioria dos GANs.
GoogleNet
Os vencedores do ISLVRC 2014, Christian Szegedy et al. apresentaram uma rede neural de 22 camadas chamada GoogleNet. É um tipo de modelo inicial e solidificou a posição do Google no espaço de visão computacional. O GoogleNet registrou uma taxa de erro de 6,7%. A principal característica dessa arquitetura é a melhor utilização dos recursos de computação dentro da rede. Isso foi conseguido por meio de um design cuidadosamente elaborado que permite aumentar a profundidade e a largura da rede, mantendo o orçamento computacional constante. O GoogleNet introduziu o conceito de módulo Inception, em que nem tudo acontece sequencialmente, como visto nas arquiteturas anteriores, mas existem certas partes da rede que estão acontecendo em paralelo.
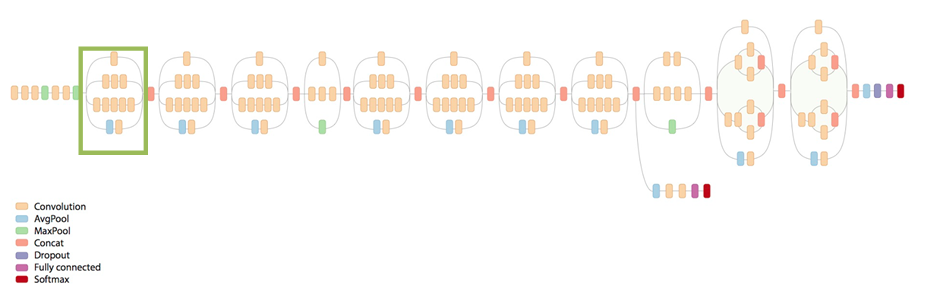
Notavelmente, a taxa de erro do GoogleNet se aproximou do desempenho humano (está na faixa de 5 a 10%). O GoogleNet foi um dos primeiros modelos a conceituar que as camadas da CNN nem sempre precisavam ser empilhadas sequencialmente. O módulo Inception garantiu que uma estruturação criativa e cuidadosa das camadas melhorasse o desempenho e a eficiência computacional.
ResNet
O ResNet da Microsoft, desenvolvido por Kaiming He, Xiangyu Zhang, Shaoqing Ren e Jian Sun, é uma estrutura de aprendizado residual para facilitar o treinamento de redes que são substancialmente mais profundas do que as usadas anteriormente. Os autores forneceram evidências empíricas abrangentes que mostram que essas redes residuais são mais fáceis de otimizar e podem obter precisão com uma profundidade consideravelmente maior.
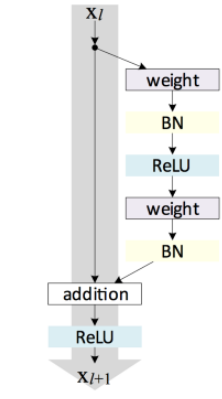
A ResNet superou o desempenho humano com uma taxa de erro de 3,57% com uma nova arquitetura de rede de 152 camadas que estabeleceu novos recordes em classificação, detecção e localização por meio de uma arquitetura incrível.
Redes de ResNets amplas
Sergey Zagoruyko e Nikos Komodakis apresentaram este artigo em 2016 com um estudo experimental detalhado sobre a arquitetura dos blocos ResNet, com base no qual eles propõem uma nova arquitetura na qual diminuem a profundidade de toda a rede e aumentam a largura das redes residuais. Aumentar a largura está usando mais mapas de recursos em camadas residuais. Embora a sabedoria comum diga que isso pode sobrecarregar a rede, na verdade funciona.
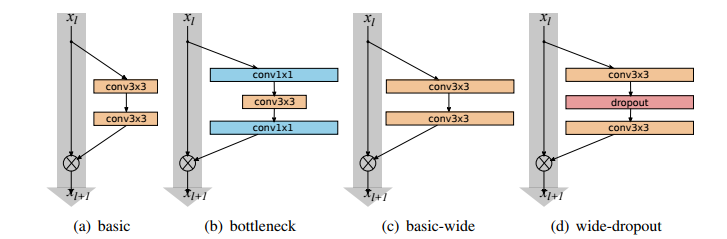
Os autores chamaram as estruturas de rede resultantes de Wide Residual Networks (WRNs) e mostraram que elas eram muito superiores às suas contrapartes finas e muito profundas comumente usadas. Um Wide ResNet pode ter de 2 a 12 vezes mais mapas de recursos em comparação com o ResNet em sua camada convolucional.
ResNext
A ResNext garantiu o segundo lugar na ILSCRV 2016. É uma arquitetura de rede simples e altamente modularizada para classificação de imagens. O design do ResNext resulta em uma arquitetura homogênea de várias filiais que tem apenas alguns hiperparâmetros para definir.
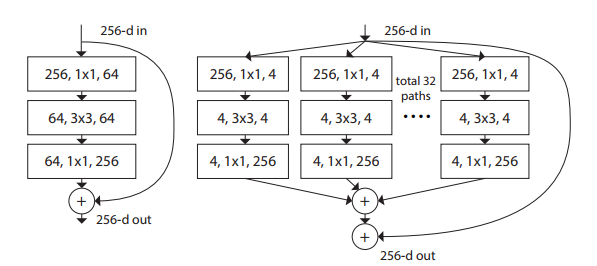
Essa estratégia expõe uma nova dimensão, que os autores chamaram de “cardinalidade” (o tamanho do conjunto de transformações), como um fator essencial, além das dimensões de profundidade e largura. Aumentar a cardinalidade é mais eficaz do que ir mais fundo ou mais amplo quando a capacidade é aumentada. Portanto, ele se saiu melhor do que os ResNets e os Wide ResNets em precisão.
Dense Net
Redes convolucionais densas, desenvolvidas por Gao Huang, Zhuang Liu, Kilian Q. Weinberger e Laurens van der Maaten em 2016, conectam cada camada a todas as outras camadas de forma progressiva. Para cada camada, os mapas de feição de todas as camadas anteriores são usados como entradas, e seus próprios mapas de feição são usados como entradas em todas as camadas subsequentes.
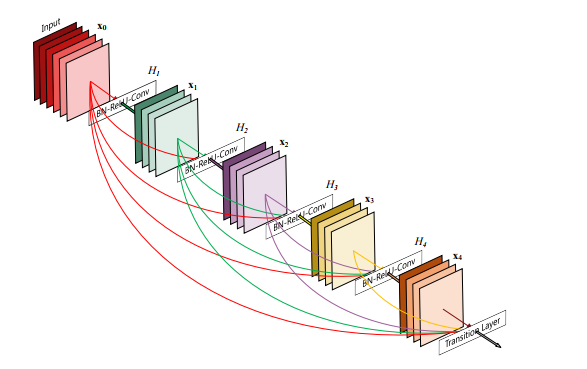
As DenseNets têm várias vantagens convincentes, como aliviar o problema do gradiente que desaparece, fortalecer a propagação de recursos, incentivar a reutilização de recursos e reduzir substancialmente o número de parâmetros. As DenseNets superaram as ResNets e, ao mesmo tempo, exigiram menos memória e computação para obter alto desempenho.
Novas arquiteturas com potencial futuro promissor
É provável que as variantes da CNN dominem o design da arquitetura de classificação de imagens. Módulos de atenção e SENETs se tornarão mais importantes no devido tempo.
EneTS
A entrada vencedora do ILSCRV 2017, Squeeze-and-Excitation Networks (Enet), trabalha em operações de compressão, excitação e escalabilidade. Em vez de introduzir um novo espaço para a integração de canais de recursos, o SENets trabalha em uma nova estratégia de “recalibração de recursos”.
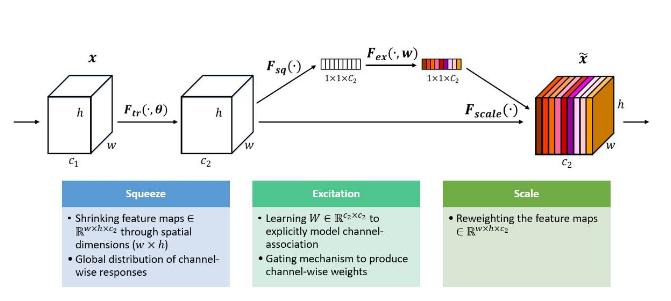
Os autores modelaram explicitamente a interdependência entre canais de recursos. O SENets é treinado para obter automaticamente a importância de cada canal de recursos e usar essa importância para aprimorar recursos úteis. No concurso ILSVRC 2017, o modelo SeNet obteve uma incrível taxa de erro Top-5 de 2,251% no conjunto de testes.
Redes de atenção residual
Rede de atenção residual, uma rede neural convolucional que usa mecanismo de atenção que pode ser incorporada à arquitetura de rede de alimentação avançada de última geração de uma forma de treinamento de ponta a ponta. O aprendizado residual de atenção é usado para treinar redes de atenção residual muito profundas, que podem ser facilmente escaladas para centenas de camadas.

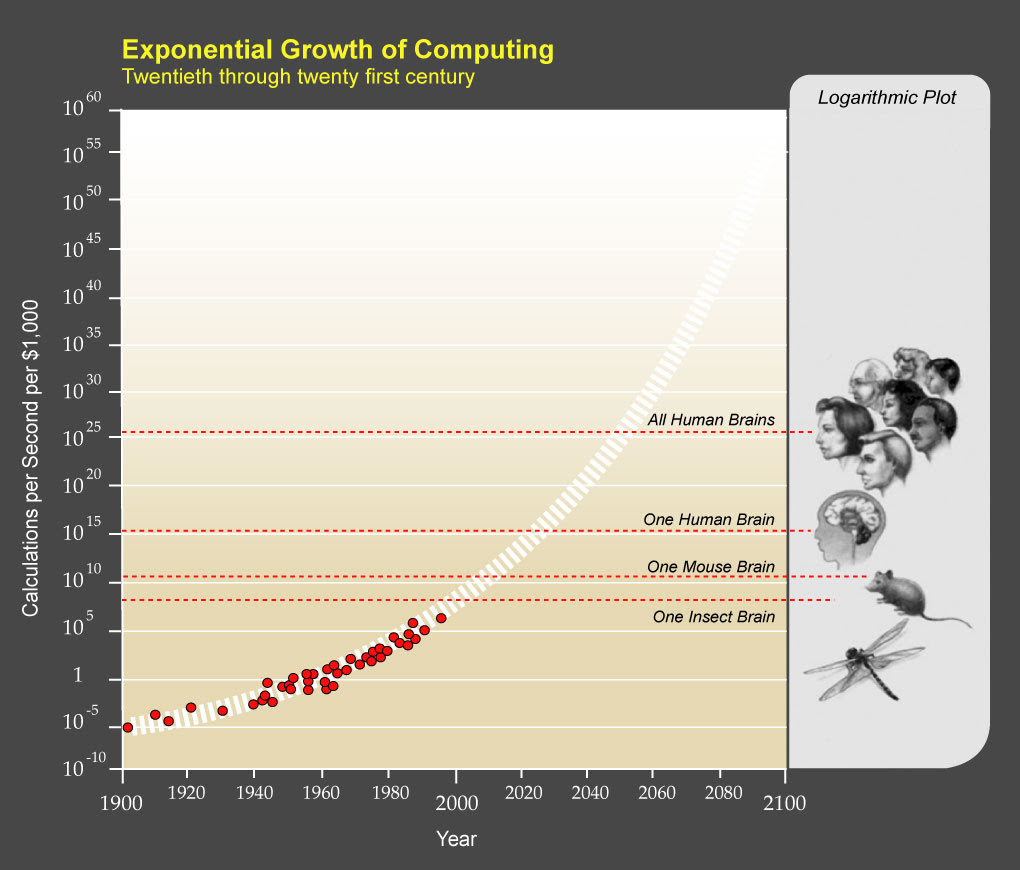
Hoje, o poder de processamento de um computador que você pode comprar por $1000 é 1/1000 da capacidade do cérebro humano. Pela lei de Moore, alcançaremos o poder computacional do cérebro humano em 2025 e de toda a humanidade em 2050. A eficácia da IA só vai acelerar com o tempo. Como a disponibilidade de dados e o poder de processamento não estão mais impedindo os pesquisadores, podemos supor que a precisão dos modelos de aprendizado profundo usados para classificação de imagens melhorará no devido tempo. Como um importante grupo de pesquisa de IA aplicada, estamos aqui para fazer parte dessa revolução.
Esperamos que você tenha gostado do artigo. Por favor Cadastre-se para obter uma conta gratuita do ParallelDots para encontrar informações interessantes sobre o que seus clientes estão dizendo. Você também pode conferir demonstrações gratuitas das APIs Komprehend AI aqui.
.png)
.png)
.png)