Share it with your network.
Die Large Scale Visual Recognition Challenge (ILSVRC) verzeichnete in den letzten Jahren einen exponentiellen Rückgang der Top-5-Fehlerrate bei der neuronalen Netzwerkarchitektur für die Bildklassifizierung
Deep-Learning-Modelle für die Bildklassifizierung haben in den letzten Jahren an Genauigkeit zugenommen. Deep Learning ist zu einem Hauptschwerpunkt der KI-Forschung geworden. Deep Learning gibt es jedoch schon seit einigen Jahrzehnten. Yann Lecun, präsentiert als Papier 1998 leistete er Pionierarbeit bei den Convolutional Neural Networks (CNN). Aber erst zu Beginn des aktuellen Jahrzehnts nahm Deep Learning wirklich Fahrt auf. In einem früheren Post wir haben einige wegweisende Forschungsarbeiten zu folgenden Themen aufgelistet Stimmungsanalyse.

Für uns Menschen ist es sehr einfach, den Inhalt eines Bildes zu verstehen. Wenn ich mir zum Beispiel einen Film (wie Herr der Ringe) anschaue, muss ich nur ein Beispiel von einem Zwerg sehen, und das ermöglicht es mir, andere Zwerge ohne Mühe zu identifizieren. Für eine Maschine ist die Aufgabe jedoch extrem schwierig, da alles, was sie auf einem Bild sehen kann, eine Reihe von Zahlen ist. Wenn die Aufgabe darin besteht, eine Katze auf einem Bild zu identifizieren, können Sie sich vorstellen, wie schwierig es ist, eine Katze aus dieser riesigen Zahlenreihe zu finden. Außerdem gibt es Katzen in allen Formen, Größen, Farben und Posen, was die Aufgabe noch schwieriger macht.
Bahnbrechende Forschungsarbeiten zur Bildklassifizierung
AlexNet
In ILSVRC 2012 präsentierten Alex Krizhevsky, Ilya Sutskever und Geoffrey Hinton AlexNet, ein tiefgründiges CNN. AlexNet verzeichnete eine Fehlerrate von 15,4% und übertraf damit den zweitbesten Eintrag um mehr als 10% (Der zweitbeste Eintrag hatte eine Fehlerquote von 26,2%). Diese beeindruckende Leistung von AlexNet hat die gesamte Computer Vision-Community im Sturm erobert und Deep Learning und CNNs zu den Disruptionen gemacht, die sie heute sind.
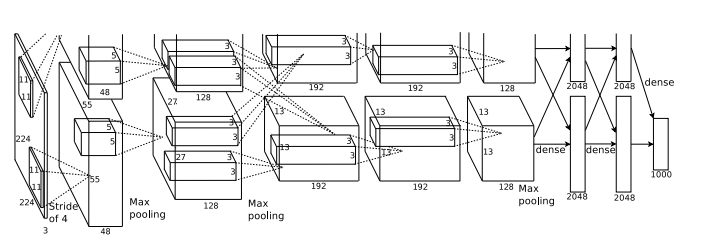
Dies war das erste Mal, dass ein Modell bei einem historisch schwierigen ImageNet-Datensatz so gut abschneidet. AlexNet legte den Grundstein für fortgeschrittenes Deep Learning. Es ist immer noch eines der am häufigsten zitierten Artikel zum Thema Deep Learning und wird etwa 7000 Mal zitiert.
ZFnet
Matthew D Zeiler (Gründer von Clarifai) und Rob Fergus gewannen 2013 den ILSVRC und übertrafen AlexNet, indem sie die Fehlerrate auf 11,2% reduzierten. ZFNet führte eine neuartige Visualisierungstechnik ein, die einen Einblick in die Funktion der dazwischenliegenden Feature-Layer und die Funktionsweise des Klassifikators gibt, die beide in AlexNet fehlten.
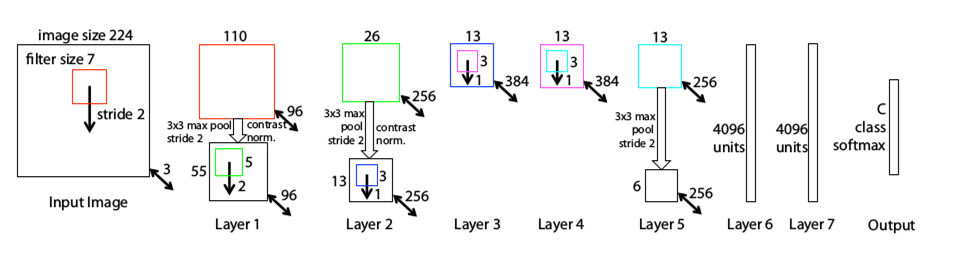
ZFNet eröffnete die Möglichkeit, verschiedene Merkmalsaktivierungen und ihre Beziehung zum Eingaberaum mit einer Technik namens Deconvolutional Network zu untersuchen.
VGG-Netz
Karen Simonyan und Andrew Zisserman von der University of Oxford erstellten ein Deep CNN, das als zweitbester Beitrag für die Bildklassifizierungsaufgabe des ISLVRC 2014 ausgewählt wurde. VGG Net hat gezeigt, dass eine deutliche Verbesserung gegenüber den bisher bekannten Konfigurationen erreicht werden kann, indem die Tiefe auf 16-19 Gewichtsschichten erhöht wird, was wesentlich tiefer ist als beim Stand der Technik.
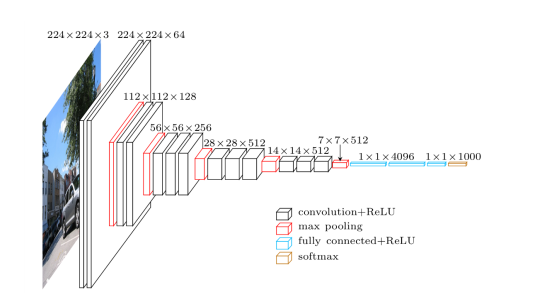
Die Architektur wurde gelobt, weil sie viel einfacher zu verstehen war (einfacher als GoogleLENet, Gewinner von ISLVRC 2014), aber dennoch eine optimale Genauigkeit erreichen konnte. Ihre Feature-Maps werden heute häufig für Transfer Learning und andere Algorithmen verwendet, für die vortrainierte Netzwerke erforderlich sind, wie bei den meisten GANs.
GoogleNet
Die Gewinner des ISLVRC 2014, Christian Szegedy et al., präsentierten ein 22-schichtiges neuronales Netzwerk namens GoogleNet. Es ist eine Art Inception-Modell und hat Googles Position im Bereich Computer Vision gefestigt. GoogleNet verzeichnete eine Fehlerrate von 6,7%. Das Hauptmerkmal dieser Architektur ist die verbesserte Nutzung der Computerressourcen im Netzwerk. Dies wurde durch ein sorgfältig ausgearbeitetes Design erreicht, das es ermöglicht, die Tiefe und Breite des Netzwerks zu erhöhen und gleichzeitig das Rechenbudget konstant zu halten. GoogleNet führte das Konzept des Inception-Moduls ein, bei dem nicht alles sequentiell abläuft, wie es bei früheren Architekturen der Fall war, sondern dass bestimmte Teile des Netzwerks parallel ablaufen.
Bemerkenswerterweise näherte sich die Fehlerrate von GoogleNet der menschlichen Leistung (liegt im Bereich von 5-10%). GoogleNet war eines der ersten Modelle, das konzeptualisierte, dass CNN-Ebenen nicht immer sequentiell gestapelt werden müssen. Das Inception-Modul sorgte dafür, dass eine kreative und sorgfältige Strukturierung der Ebenen die Leistung und die Recheneffizienz verbessert.
ResNet
ResNet von Microsoft, das von Kaiming He, Xiangyu Zhang, Shaoqing Ren und Jian Sun entwickelt wurde, ist ein Restlern-Framework, das das Training von Netzwerken erleichtert, die wesentlich tiefer sind als die zuvor verwendeten. Die Autoren lieferten umfassende empirische Belege dafür, dass diese verbleibenden Netzwerke leichter zu optimieren sind und durch eine erheblich größere Tiefe an Genauigkeit gewinnen können.
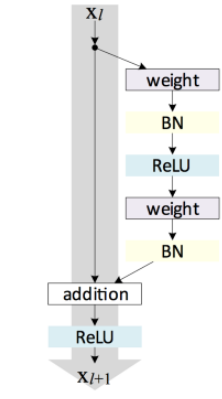
ResNet übertraf die menschliche Leistung mit einer Fehlerrate von 3,57% mit einer neuen 152-Schichten-Netzwerkarchitektur, die durch eine unglaubliche Architektur neue Rekorde bei der Klassifizierung, Erkennung und Lokalisierung aufstellte.
Breite ResNets
Sergey Zagoruyko und Nikos Komodakis präsentierten diesen Artikel 2016 mit einer detaillierten experimentellen Studie zur Architektur von ResNet-Blöcken, auf deren Grundlage sie eine neuartige Architektur vorschlagen, bei der sie die Tiefe des gesamten Netzwerks verringern und die Breite der verbleibenden Netzwerke erhöhen. Bei zunehmender Breite werden mehr Feature-Maps in den verbleibenden Schichten verwendet. Obwohl allgemein bekannt ist, dass dies das Netzwerk überfordern könnte, funktioniert es tatsächlich.
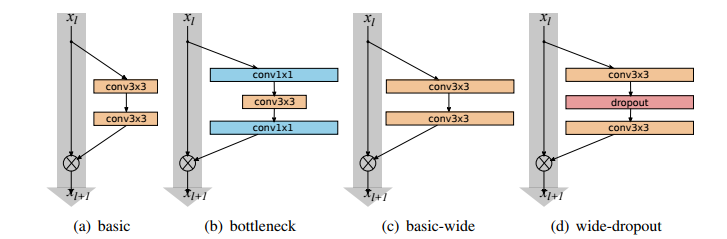
Die Autoren nannten die resultierenden Netzwerkstrukturen Wide Residual Networks (WRNs) und zeigten, dass diese ihren häufig verwendeten dünnen und sehr tiefen Gegenstücken weit überlegen waren. Ein Wide ResNet kann im Vergleich zu ResNet in seiner Faltungsschicht 2-12-mal mehr Feature-Maps enthalten.
ResWeiter
ResNext sicherte sich den zweiten Platz bei ILSCRV 2016. Es handelt sich um eine einfache, stark modularisierte Netzwerkarchitektur zur Bildklassifizierung. Das ResNext-Design führt zu einer homogenen Architektur mit mehreren Zweigen, für die nur wenige Hyperparameter eingestellt werden müssen.
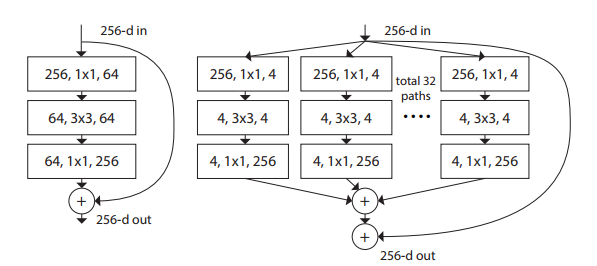
Diese Strategie enthüllt eine neue Dimension, die die Autoren „Kardinalität“ (die Größe der Menge von Transformationen) nannten, als wesentlichen Faktor zusätzlich zu den Dimensionen Tiefe und Breite. Eine Erhöhung der Kardinalität ist effektiver, als bei einer Erhöhung der Kapazität tiefer oder breiter vorzugehen. Daher schnitt es hinsichtlich der Genauigkeit besser ab als ResNets und Wide ResNets.
Dichtes Netz
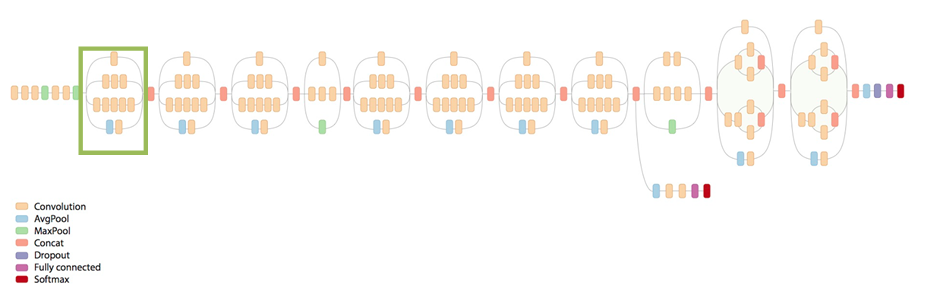
Dense Convolutional Networks, 2016 von Gao Huang, Zhuang Liu, Kilian Q. Weinberger und Laurens van der Maaten entwickelt, verbindet jede Ebene per Feed-Forward mit jeder anderen Ebene. Für jede Ebene werden die Feature-Maps aller vorhergehenden Ebenen als Eingaben verwendet, und ihre eigenen Feature-Maps werden als Eingaben für alle nachfolgenden Ebenen verwendet.
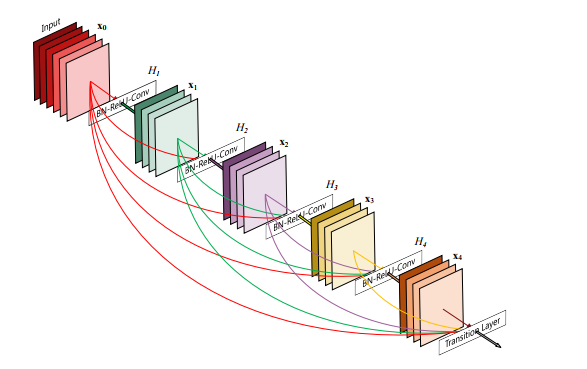
DenseNETS haben mehrere überzeugende Vorteile, wie z. B. die Linderung des Problems des Verschwindungsgradienten, die Stärkung der Merkmalsausbreitung, die Förderung der Wiederverwendung von Merkmalen und die erhebliche Reduzierung der Anzahl der Parameter. DenseNets übertraf ResNets und benötigte gleichzeitig weniger Speicher und Rechenleistung, um eine hohe Leistung zu erzielen.
Neue Architekturen mit vielversprechendem Zukunftspotenzial
Die Varianten von CNN werden wahrscheinlich das Architekturdesign der Image Classification dominieren. Achtung Module und SENETS werden zu gegebener Zeit an Bedeutung gewinnen.
E NETS
Der Gewinnerbeitrag von ILSCRV 2017, Squeeze-and-Excitation Networks (im Netz), funktioniert bei Squeeze-, Excitations- und Scaling-Operationen. Anstatt ein neues räumliches System für die Integration von Merkmalskanälen einzuführen, arbeitet SeNETS an einer neuen Strategie zur Neukalibrierung von Merkmalen.
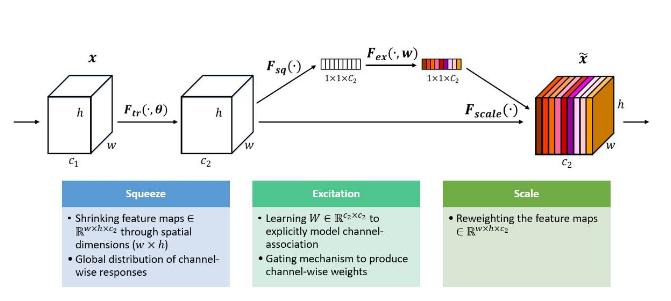
Die Autoren modellierten explizit die Interdependenz zwischen Feature-Kanälen. SeNETS ist darauf trainiert, die Wichtigkeit jedes Feature-Kanals automatisch zu ermitteln und diese Bedeutung zu nutzen, um nützliche Funktionen zu verbessern. Beim ILSVRC-Wettbewerb 2017 erzielte das SeNet-Modell auf dem Testgerät eine unglaubliche Top-5-Fehlerrate von 2,251%.
Restaufmerksamkeitsnetzwerke
Residual Attention Network, ein neuronales Faltungsnetzwerk, das einen Aufmerksamkeitsmechanismus verwendet und in eine hochmoderne Feed-Forward-Netzwerkarchitektur integriert werden kann, um ein durchgängiges Training zu ermöglichen. Das Restaufmerksamkeitslernen wird verwendet, um sehr tiefe Restaufmerksamkeitsnetzwerke zu trainieren, die leicht auf Hunderte von Ebenen skaliert werden können.

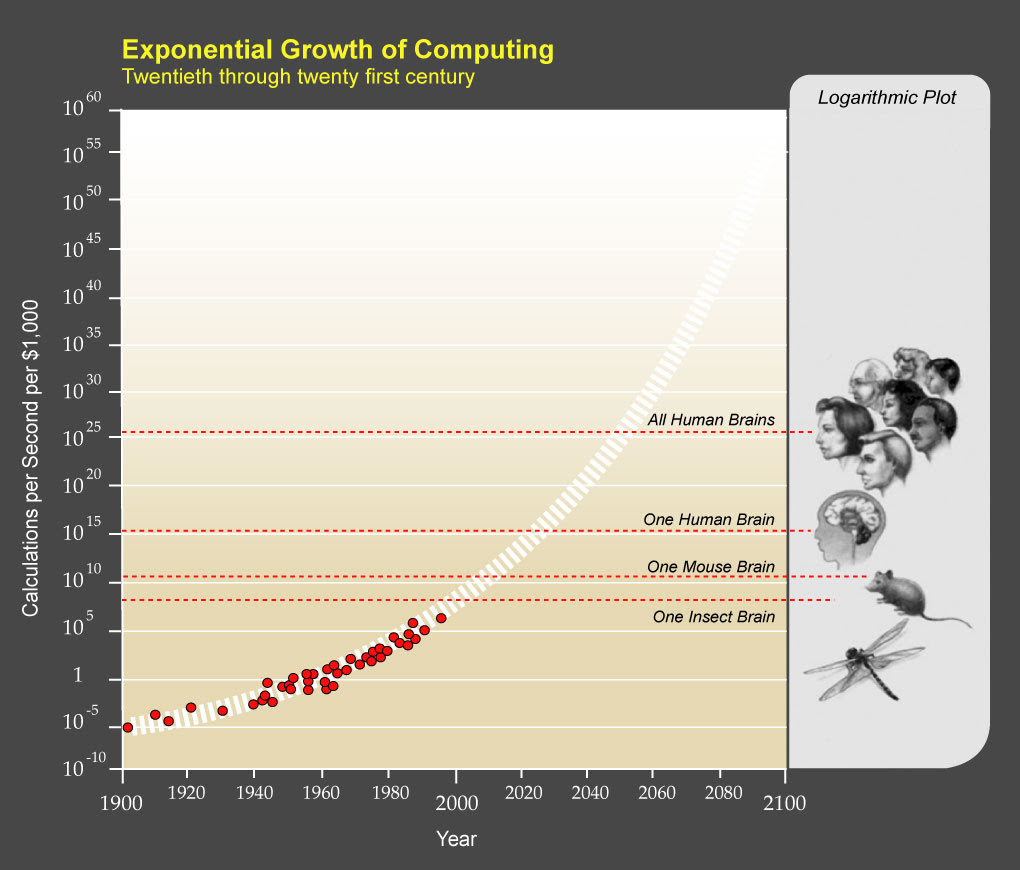
Heute beträgt die Rechenleistung eines Computers, den Sie für 1000 US-Dollar kaufen können, 1/1000 der Kapazität des menschlichen Gehirns. Nach dem Mooreschen Gesetz werden wir bis 2025 die Rechenleistung des menschlichen Gehirns erreichen und bis 2050 die gesamte Menschheit. Die Effektivität der KI wird sich mit der Zeit nur beschleunigen. Da die Verfügbarkeit von Daten und die Rechenleistung die Forscher nicht mehr aufhalten, können wir davon ausgehen, dass die Genauigkeit der für die Bildklassifizierung verwendeten Deep-Learning-Modelle zu gegebener Zeit besser werden wird. Als führende Forschungsgruppe für angewandte KI sind wir hier, um Teil dieser Revolution zu sein.
Wir hoffen, dir hat der Artikel gefallen. Bitte Melde dich an für ein kostenloses ParallelDots-Konto, um interessante Einblicke in das zu erhalten, was Ihre Kunden sagen. Sie können sich auch kostenlose Demos der Komprehend AI-APIs ansehen hier.


.png)