Share it with your network.
Os profissionais de aprendizado de máquina têm personalidades diferentes. Enquanto alguns deles são “Eu sou um especialista em X e X posso treinar com qualquer tipo de dado”, onde X = algum algoritmo, outros são “A ferramenta certa para os funcionários certos”. Muitos deles também assinam o “Jack of all trades”. Mestre em uma estratégia “única”, na qual eles têm uma área de profunda especialização e conhecem um pouco sobre diferentes campos do aprendizado de máquina. Dito isso, ninguém pode negar o fato de que, como cientistas de dados praticantes, precisaremos conhecer o básico de alguns algoritmos comuns de aprendizado de máquina, o que nos ajudaria a lidar com um problema de novo domínio que encontramos. Este é um passeio rápido por algoritmos comuns de aprendizado de máquina e recursos rápidos sobre eles que podem ajudar você a começar a usá-los.
1. Análise de componentes principais (PCA) /SVD
O PCA é um método não supervisionado para entender as propriedades globais de um conjunto de dados que consiste em vetores. A matriz de covariância de pontos de dados é analisada aqui para entender quais dimensões (principalmente) /pontos de dados (às vezes) são mais importantes (ou seja, têm alta variância entre si, mas baixa covariância com outras). Uma maneira de pensar nos principais PCs de uma matriz é pensar em seus autovetores com valores próprios mais altos. O SVD também é essencialmente uma forma de calcular componentes ordenados, mas você não precisa obter a matriz de covariância de pontos para obtê-la.

Esse algoritmo ajuda a combater a maldição da dimensionalidade obtendo pontos de dados com dimensões reduzidas.
Bibliotecas:
Tutorial introdutório:
Um tutorial sobre análise de componentes principais
2a. Mínimos quadrados e ajuste polinomial
Lembre-se do seu código de análise numérica na faculdade, onde você costumava ajustar linhas e curvas a pontos para obter uma equação. Você pode usá-los para ajustar curvas no Machine Learning para conjuntos de dados muito pequenos com dimensões baixas. (Para dados grandes ou conjuntos de dados com várias dimensões, você pode acabar se ajustando muito, então não se preocupe). O OLS tem uma solução de formato fechado, então você não precisa usar técnicas de otimização complexas.
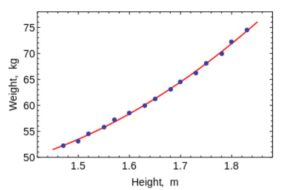
Como é óbvio, use esse algoritmo para ajustar curvas simples//regressão
Bibliotecas:
Tutorial introdutório:
2b. Regressão linear restrita
Os mínimos quadrados podem ser confundidos com valores discrepantes, campos espúrios e ruídos nos dados. Portanto, precisamos de restrições para diminuir a variância da linha que ajustamos em um conjunto de dados. O método correto para fazer isso é ajustar um modelo de regressão linear que garantirá que os pesos não se comportem mal. Os modelos podem ter a norma L1 (LASSO) ou L2 (Regressão Ridge) ou ambas (regressão elástica). A perda quadrática média é otimizada.
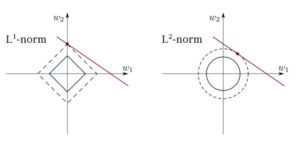
Use esses algoritmos para ajustar as linhas de regressão com restrições, evitando o sobreajuste e mascarando as dimensões de ruído do modelo.
Bibliotecas:
Tutorial (s) introdutório (s):
3. K significa Agrupamento
O algoritmo de agrupamento não supervisionado favorito de todos. Dado um conjunto de pontos de dados na forma de vetores, podemos criar grupos de pontos com base nas distâncias entre eles. É um algoritmo de maximização de expectativas que move iterativamente os centros dos clusters e, em seguida, agrupa os pontos com cada centro do cluster. A entrada que o algoritmo recebeu é o número de clusters que devem ser gerados e o número de iterações nas quais ele tentará convergir os clusters.

Como fica óbvio pelo nome, você pode usar esse algoritmo para criar K clusters no conjunto de dados
Biblioteca:
Tutorial (s) introdutório (s):
Introdução ao agrupamento K-means
4. Regressão logística
A regressão logística é uma aplicação de regressão linear restrita com uma aplicação de não linearidade (a função sigmóide é usada principalmente ou você também pode usar tanh) após a aplicação dos pesos, restringindo assim as saídas próximas às classes +/- (que são 1 e 0 no caso do sigmóide). As funções de perda de entropia cruzada são otimizadas usando gradiente descendente. Uma nota para iniciantes: a regressão logística é usada para classificação, não regressão. Você também pode pensar na regressão logística como uma rede neural de uma camada. A regressão logística é treinada usando métodos de otimização como Gradient Descent ou L-BFGS. As pessoas da PNL geralmente a usam com o nome de Classificador de Entropia Máxima.
Esta é a aparência de um sigmóide:

Use o LR para treinar classificadores simples, mas muito robustos.
Biblioteca:
sklearn.linear_model.Regressão logística
Tutorial (s) introdutório (s):
Regressão logística - Classificação
5. SVM (máquinas vetoriais de suporte)
Os SVMs são modelos lineares, como regressão linear/logística, a diferença é que eles têm diferentes funções de perda baseadas em margens (a derivação de vetores de suporte é um dos resultados matemáticos mais bonitos que já vi junto com o cálculo de autovalores). Você pode otimizar a função de perda usando métodos de otimização como L-BFGS ou até mesmo SGD.

Outra inovação em SVMs é o uso de kernels em dados para engenharia de recursos. Se você tiver uma boa visão do domínio, poderá substituir o bom e velho kernel RBF por outros mais inteligentes e lucrar.
Uma coisa única que os SVMs podem fazer é aprender classificadores de uma classe.
SVMs podem ser usados para treinar um classificador (até mesmo regressores)
Biblioteca:
Tutorial (s) introdutório (s):
Nota: O treinamento baseado em SGD de regressão logística e SVMs é encontrado no SkLearn
Classificador sklearn.linear_model.sgdClassificador, que eu uso com frequência, pois permite verificar o LR e o SVM com uma interface comum. Você também pode treiná-lo em conjuntos de dados do tamanho de >RAM usando mini lotes.
6. Redes neurais Feedforward
Esses são basicamente classificadores de regressão logística multicamada. Muitas camadas de pesos separadas por não linearidades (sigmoide, tanh, relu + softmax e o cool new selu). Outro nome popular para eles é Perceptrons de várias camadas. Os FFNNs podem ser usados para classificação e aprendizado de recursos não supervisionado como codificadores automáticos.
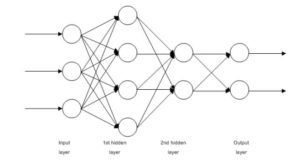
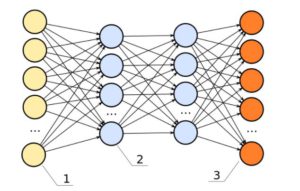
Os FFNNs podem ser usados para treinar um classificador ou extrair recursos como codificadores automáticos.
Bibliotecas:
Classificador sklearn.neural_network.mlp
sklearn.neural_network.mlp
Comparação de MLPs autornormalizáveis com MLPs regulares
Tutorial (s) introdutório (s):
7. Redes neurais convolucionais (Convnets)
Quase todos os resultados de aprendizado de máquina baseados em visão de última geração no mundo atual foram alcançados usando redes neurais convolucionais. Eles podem ser usados para classificação de imagens, detecção de objetos ou até mesmo segmentação de imagens. Inventados por Yann Lecun no final dos anos 80 e início dos anos 90, os Convnets apresentam camadas convolucionais que atuam como extratores de características hierárquicas. Você também pode usá-los em texto (e até em gráficos).

Use conventos para classificação de imagens e textos de última geração, detecção de objetos e segmentação de imagens.
Bibliotecas:
Sistema de treinamento de GPU de aprendizado profundo (DIGITS)
TorchCV: uma biblioteca de visão do PyTorch imita o ChainerCV
ChainerCV: uma biblioteca para aprendizado profundo em visão computacional
Tutorial (s) introdutório (s):
CS231n: Redes neurais convolucionais para reconhecimento visual.
Um guia para iniciantes para entender as redes neurais convolucionais
8. Redes neurais recorrentes (RNNs):
Os RNNs modelam sequências aplicando o mesmo conjunto de pesos recursivamente no estado agregador no momento t e na entrada no momento t (dado que uma sequência tem entradas nos momentos 0.. t.. T e tem um estado oculto a cada momento t que é gerado pela etapa t-1 do RNN). RNNs puros raramente são usados agora, mas suas contrapartes, como LSTMs e GRUs, são o estado da arte na maioria das tarefas de modelagem de sequência.
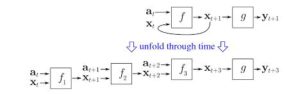
RNN (Se houver uma unidade densamente conectada e uma não linearidade, hoje em dia f é geralmente LSTMs ou GRus). Unidade LSTM que é usada em vez de uma camada densa simples em um RNN puro.
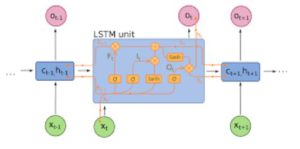
Use RNNs para qualquer tarefa de modelagem de sequência, especialmente classificação de texto, tradução automática e modelagem de linguagem
Biblioteca:
Modelos e exemplos criados com o TensorFlow (Muitos artigos interessantes de pesquisa sobre PNL do Google estão aqui)
Uma referência de classificação de texto em PyTorch
Tutorial (s) introdutório (s):
CS224d: Aprendizado profundo para processamento de linguagem natural
RNNs no Tensorflow, um guia prático e recursos não documentados
9. Campos aleatórios condicionais (CRFs)
Os CRFs são provavelmente os modelos mais usados da família de Modelos Gráficos Probabilíticos (PGMs). Eles são usados para modelagem de sequência como RNNs e também podem ser usados em combinação com RNNs. Antes da chegada dos sistemas de tradução automática neural, os CRFs eram o estado da arte e, em muitas tarefas de marcação de sequência com pequenos conjuntos de dados, eles ainda aprenderão melhor do que os RNNs, que exigem uma quantidade maior de dados para serem generalizados. Eles também podem ser usados em outras tarefas de previsão estruturada, como segmentação de imagens, etc. O CRF modela cada elemento da sequência (digamos, uma frase) de forma que os vizinhos afetem o rótulo de um componente em uma sequência, em vez de todos os rótulos serem independentes uns dos outros.
Use CRFs para marcar sequências (em texto, imagem, séries temporais, DNA etc.)
Biblioteca:
Tutorial (s) introdutório (s):
Introdução aos campos aleatórios condicionais
Série de palestras de 10 partes sobre CRFs por Hugo Larochelle
10. Árvores de decisão
Digamos que eu receba uma planilha do Excel com dados sobre várias frutas e eu tenha que dizer quais se parecem com maçãs. O que vou fazer é fazer uma pergunta “Quais frutas são vermelhas e redondas?” e divida todas as frutas que respondem sim e não à pergunta. Agora, todas as frutas vermelhas e redondas podem não ser maçãs e nem todas as maçãs serão vermelhas e redondas. Então, vou fazer uma pergunta: “Quais frutas têm notas de vermelho ou amarelo? ” em frutas vermelhas e redondas e perguntará “Quais frutas são verdes e redondas?” em frutas não vermelhas e redondas. Com base nessas perguntas, posso dizer com considerável precisão quais são as maçãs. Essa cascata de perguntas é o que é uma árvore de decisão. No entanto, esta é uma árvore de decisão baseada na minha intuição. A intuição não pode funcionar com dados complexos e de alta dimensão. Temos que criar a cascata de perguntas automaticamente analisando os dados marcados. É isso que as árvores de decisão baseadas em aprendizado de máquina fazem. Versões anteriores, como as árvores CART, já foram usadas para dados simples, mas com um conjunto de dados cada vez maior, a compensação entre viés e variância precisa ser resolvida com algoritmos melhores. Os dois algoritmos comuns de árvores de decisão usados atualmente são Random Forests (que constroem classificadores diferentes em um subconjunto aleatório de atributos e os combinam para gerar resultados) e Boosting Trees (que treinam uma cascata de árvores umas sobre as outras, corrigindo os erros das que estão abaixo delas).
As árvores de decisão podem ser usadas para classificar pontos de dados (e até mesmo regressão)
Bibliotecas
Sklearn.ensemble.RandomForest Classifier
sklearn.ensemble.GradientBoostingClassifier
Tutorial introdutório:
Uma excursão guiada aleatória pela floresta
Entendendo florestas aleatórias: da teoria à prática
Algoritmos TD (é bom ter)
Se você ainda está se perguntando como qualquer um dos métodos acima pode resolver tarefas como derrotar o campeão mundial de Go, como fez a DeepMind, eles não podem. Todos os 10 tipos de algoritmos sobre os quais falamos antes eram reconhecimento de padrões, não aprendizes de estratégia. Para aprender estratégias para resolver um problema de várias etapas, como vencer uma partida de xadrez ou jogar no console Atari, precisamos deixar um agente livre no mundo e aprender com as recompensas e penalidades que ele enfrenta. Esse tipo de aprendizado de máquina é chamado de aprendizado por reforço. Muitos (não todos) dos sucessos recentes na área são resultado da combinação das habilidades de percepção de um Convnet ou LSTM a um conjunto de algoritmos chamado Aprendizado por Diferenças Temporais. Isso inclui Q-Learning, SARSA e algumas outras variantes. Esses algoritmos são uma jogada inteligente com as equações de Bellman para obter uma função de perda que possa ser treinada com recompensas que um agente recebe do ambiente.
Esses algoritmos são usados principalmente para jogar jogos automática:D, além de outras aplicações na geração de linguagem e detecção de objetos.
Bibliotecas:
Aprendizado por reforço profundo para Keras
Uma implementação de código aberto do algoritmo AlphaGoZero
Tutorial (s) introdutório (s):
Assista ao curso de David Silver sobre RL
Esses são os 10 algoritmos de aprendizado de máquina que você pode aprender para se tornar um cientista de dados.
Esperamos que você tenha gostado do artigo. Por favor Cadastre-se para obter uma conta gratuita do Komprehend para iniciar sua jornada de IA. Você também pode conferir demonstrações das APIs Komprehend AI aqui.
.png)
.png)
.png)