Share it with your network.
Praktiker des maschinellen Lernens haben unterschiedliche Persönlichkeiten. Während einige von ihnen sagen: „Ich bin ein Experte in X und X kann mit jeder Art von Daten trainieren“, wobei X für einen Algorithmus steht, andere sind „Das richtige Werkzeug für die richtigen Mitarbeiter“. Viele von ihnen abonnieren auch den „Alleskönner“. „Master of One“ -Strategie, bei der sie über ein Fachgebiet mit fundiertem Fachwissen verfügen und sich in verschiedenen Bereichen des maschinellen Lernens ein wenig auskennen. Allerdings kann niemand die Tatsache leugnen, dass wir als praktizierende Datenwissenschaftler die Grundlagen einiger gängiger Algorithmen für maschinelles Lernen kennen müssen, was uns helfen würde, ein neues Domänenproblem zu lösen, auf das wir stoßen. Dies ist eine spannende Tour durch gängige Algorithmen für maschinelles Lernen und kurze Ressourcen zu ihnen, die Ihnen den Einstieg erleichtern können.
1. Hauptkomponentenanalyse (PCA) /SVD
PCA ist eine unbeaufsichtigte Methode zum Verständnis der globalen Eigenschaften eines Datensatzes, der aus Vektoren besteht. Die Kovarianzmatrix der Datenpunkte wird hier analysiert, um zu verstehen, welche Dimensionen (meistens)/Datenpunkte (manchmal) wichtiger sind (d. h. sie weisen untereinander eine hohe Varianz auf, aber eine geringe Kovarianz mit anderen). Eine Möglichkeit, sich die besten PCs einer Matrix vorzustellen, besteht darin, sich ihre Eigenvektoren mit den höchsten Eigenwerten vorzustellen. SVD ist im Grunde auch eine Methode, um geordnete Komponenten zu berechnen, aber Sie müssen nicht die Kovarianzmatrix der Punkte ermitteln, um sie zu erhalten.

Dieser Algorithmus hilft dabei, den Fluch der Dimensionalität zu bekämpfen, indem er Datenpunkte mit reduzierten Abmessungen erhält.
Bibliotheken:
Einführendes Tutorial:
Ein Tutorial zur Hauptkomponentenanalyse
2a. Kleinste Quadrate und Polynomanpassung
Erinnern Sie sich an Ihren Code für Numerische Analysis im College, wo Sie Linien und Kurven an Punkte angepasst haben, um eine Gleichung zu erhalten. Sie können sie verwenden, um Kurven im maschinellen Lernen für sehr kleine Datensätze mit niedrigen Abmessungen anzupassen. (Bei großen Daten oder Datensätzen mit vielen Dimensionen könnte es am Ende zu einer starken Überanpassung kommen, also machen Sie sich keine Mühe). OLS bietet eine Lösung für geschlossene Formulare, sodass Sie keine komplexen Optimierungstechniken verwenden müssen.
Wie es offensichtlich ist, verwenden Sie diesen Algorithmus, um einfache Kurven/Regression anzupassen
Bibliotheken:
Einführendes Tutorial:
2b. Eingeschränkte lineare Regression
Kleinste Quadrate können mit Ausreißern, Störfeldern und Rauschen in Daten verwechselt werden. Wir benötigen daher Beschränkungen, um die Varianz der Linie, die wir an einen Datensatz anpassen, zu verringern. Die richtige Methode hierfür ist die Anpassung eines linearen Regressionsmodells, das sicherstellt, dass sich die Gewichte nicht falsch verhalten. Modelle können die Norm L1 (LASSO) oder L2 (Ridge-Regression) oder beide (elastische Regression) haben. Der mittlere quadratische Verlust ist optimiert.
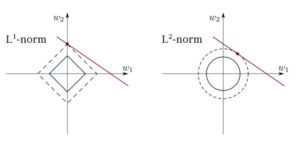
Verwenden Sie diese Algorithmen, um Regressionslinien mit Beschränkungen anzupassen und so eine Überanpassung und Maskierung der Rauschdimensionen aus dem Modell zu vermeiden.
Bibliotheken:
Einführendes Tutorial (s):
3. K bedeutet Clustering
Jedermanns Lieblingsalgorithmus für unbeaufsichtigtes Clustering. Wenn wir eine Reihe von Datenpunkten in Form von Vektoren verwenden, können wir Cluster von Punkten erstellen, die auf den Entfernungen zwischen ihnen basieren. Es handelt sich um einen Algorithmus zur Maximierung der Erwartungen, der die Zentren von Clustern iterativ verschiebt und dann Punkte mit jedem Clustermittelpunkt verknüpft. Die Eingabe, die der Algorithmus verwendet hat, ist die Anzahl der Cluster, die generiert werden sollen, und die Anzahl der Iterationen, in denen versucht wird, Cluster zu konvergieren.

Wie aus dem Namen hervorgeht, können Sie diesen Algorithmus verwenden, um K-Cluster in einem Datensatz zu erstellen
Bibliothek:
Einführendes Tutorial (s):
Einführung in das K-Means-Clustering
4. Logistische Regression
Logistische Regression ist eine eingeschränkte lineare Regression mit einer Nichtlinearitätsanwendung (die Sigmoidfunktion wird meistens verwendet oder Sie können auch tanh verwenden), nachdem Gewichte angewendet wurden, wodurch die Ausgaben in der Nähe von +/- Klassen begrenzt werden (was 1 und 0 im Fall von Sigmoid ist). Die Funktionen zum Verlust der Entropie durch Kreuzentropie werden mithilfe des Gradientenabstiegs optimiert. Ein Hinweis für Anfänger: Die logistische Regression wird zur Klassifikation verwendet, nicht zur Regression. Sie können sich die logistische Regression auch als ein einlagiges neuronales Netzwerk vorstellen. Die logistische Regression wird mit Optimierungsmethoden wie Gradient Descent oder L-BFGS trainiert. NLP-Leute verwenden es oft mit dem Namen Maximum Entropy Classifier.
So sieht ein Sigmoid aus:

Verwenden Sie LR, um einfache, aber sehr robuste Klassifikatoren zu trainieren.
Bibliothek:
sklearn.linear_model.logistische Regression
Einführendes Tutorial (s):
Logistische Regression — Klassifikation
5. SVM (Support Vector Machines)
SVMs sind lineare Modelle wie die lineare/logistische Regression. Der Unterschied besteht darin, dass sie eine unterschiedliche marginbasierte Verlustfunktion haben (Die Ableitung von Unterstützungsvektoren ist zusammen mit der Eigenwertberechnung eines der schönsten mathematischen Ergebnisse, die ich je gesehen habe). Sie können die Verlustfunktion mit Optimierungsmethoden wie L-BFGS oder sogar SGD optimieren.

Eine weitere Innovation bei SVMs ist die Verwendung von Kerneln auf Daten für den Feature-Engineer. Wenn Sie einen guten Einblick in die Domäne haben, können Sie den guten alten RBF-Kernel durch intelligentere ersetzen und profitieren.
Eine einzigartige Sache, die SVMs tun können, ist das Erlernen von Klassifikatoren für eine Klasse.
SVMs können verwendet werden, um einen Klassifikator zu trainieren (sogar Regressoren)
Bibliothek:
Einführendes Tutorial (s):
Unterstützen Sie Vektor-Maschinen
Hinweis: SGD-basiertes Training sowohl für logistische Regression als auch für SVMs finden Sie in SkLearn
sklearn.linear_model.sgd Klassifikator, das ich oft verwende, da ich damit sowohl LR als auch SVM mit einer gemeinsamen Schnittstelle überprüfen kann. Sie können es auch mit Mini-Batches an Datensätzen mit >RAM-Größe trainieren.
6. Neuronale Feedforward-Netze
Dies sind im Grunde mehrschichtige Klassifikatoren der logistischen Regression. Viele Gewichtsebenen, die durch Nichtlinearitäten voneinander getrennt sind (Sigmoid, Tanh, Relu + Softmax und das coole neue Selu). Ein weiterer beliebter Name für sie ist Multi-Layered Perceptrons. FFNNs können zur Klassifizierung und zum unbeaufsichtigten Feature-Lernen als Autoencoder verwendet werden.
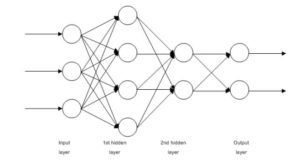
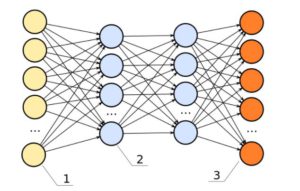
FFNNs können verwendet werden, um einen Klassifikator zu trainieren oder Merkmale als Autoencoder zu extrahieren
Bibliotheken:
sklearn.neural_network.mlp Klassifikator
sklearn.neural_network.mlp Regressor
Vergleich von selbstnormalisierenden MLPs mit regulären MLPs
Einführendes Tutorial (s):
7. Faltungsneuronale Netze (Konvents)
Fast jedes auf dem neuesten Stand der Technik basierende Ergebnis maschinellen Lernens auf der Welt wurde heute mithilfe von Convolutional Neural Networks erzielt. Sie können zur Bildklassifizierung, Objekterkennung oder sogar zur Segmentierung von Bildern verwendet werden. Konvnets wurden Ende der 80er und Anfang der 90er Jahre von Yann Lecun erfunden und bestehen aus Faltungsschichten, die als hierarchische Merkmalsextraktoren dienen. Sie können sie auch in Text (und sogar in Grafiken) verwenden.

Verwenden Sie Konvents für hochmoderne Bild- und Textklassifizierung, Objekterkennung und Bildsegmentierung.
Bibliotheken:
Deep-Learning-GPU-Schulungssystem (DIGITS)
TorchCV: Eine PyTorch-Vision-Bibliothek ahmt ChainerCV nach
ChainerCV: eine Bibliothek für Deep Learning in Computer Vision
Einführendes Tutorial (s):
CS231n: Faltungsneuronale Netze für die visuelle Erkennung.
Ein Leitfaden für Anfänger zum Verständnis neuronaler Faltungsnetzwerke
8. Wiederkehrende neuronale Netze (RNNs):
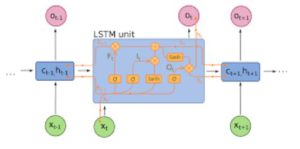
RNNs modellieren Sequenzen, indem sie den gleichen Satz von Gewichten rekursiv auf den Aggregatorzustand zu einem Zeitpunkt t anwenden und zu einem Zeitpunkt t eingegeben werden (vorausgesetzt, eine Sequenz hat Eingaben zu den Zeiten 0.. t.. T und hat zu jedem Zeitpunkt t einen versteckten Zustand, der aus dem t-1-Schritt von RNN ausgegeben wird). Reine RNNs werden derzeit selten verwendet, aber ihre Gegenstücke wie LSTMs und GRUs sind bei den meisten Sequenzmodellierungsaufgaben auf dem neuesten Stand der Technik.
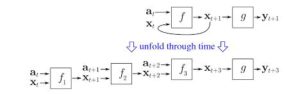
RNN (Wenn es eine dicht verbundene Einheit und eine Nichtlinearität gibt, ist f heutzutage im Allgemeinen LSTMs oder GRus). LSTM-Einheit, die anstelle einer einfachen dichten Schicht in einem reinen RNN verwendet wird.
Verwenden Sie RNNs für jede Sequenzmodellierungsaufgabe, insbesondere für Textklassifizierung, maschinelle Übersetzung, Sprachmodellierung
Bibliothek:
Mit TensorFlow erstellte Modelle und Beispiele (Viele coole NLP-Forschungsarbeiten von Google sind hier)
Ein Benchmark für die Textklassifizierung in PyTorch
Einführendes Tutorial (s):
CS224d: Deep Learning für die Verarbeitung natürlicher Sprache
RNNs in Tensorflow, ein praktischer Leitfaden und undokumentierte Funktionen
9. Bedingte Zufallsfelder (CRFs)
CRFs sind wahrscheinlich die am häufigsten verwendeten Modelle aus der Familie der probabilistischen grafischen Modelle (PGMs). Sie werden wie RNNs für die Sequenzmodellierung verwendet und können auch in Kombination mit RNNs verwendet werden. Bevor neuronale maschinelle Übersetzungssysteme auf den Markt kamen, waren CRFs auf dem neuesten Stand der Technik, und bei vielen Sequenz-Tagging-Aufgaben mit kleinen Datensätzen lernen sie immer noch besser als RNNs, für deren Generalisierung eine größere Datenmenge erforderlich ist. Sie können auch in anderen strukturierten Vorhersageaufgaben wie Bildsegmentierung usw. verwendet werden. CRF modelliert jedes Element der Sequenz (z. B. einen Satz) so, dass Nachbarn eine Bezeichnung einer Komponente in einer Sequenz beeinflussen, anstatt dass alle Beschriftungen unabhängig voneinander sind.
Verwenden Sie CRFs, um Sequenzen zu taggen (in Text, Bild, Zeitreihen, DNA usw.)
Bibliothek:
Einführendes Tutorial (s):
Einführung in bedingte Zufallsfelder
10-teilige Vorlesungsreihe über CRFs von Hugo Larochelle
10. Entscheidungsbäume
Nehmen wir an, ich erhalte eine Excel-Tabelle mit Daten zu verschiedenen Früchten und ich muss sagen, welche wie Äpfel aussehen. Ich werde eine Frage stellen: „Welche Früchte sind rot und rund?“ und teile alle Früchte auf, die die Frage mit Ja und Nein beantworten. Nun, alle roten und runden Früchte sind vielleicht keine Äpfel und nicht alle Äpfel sind rot und rund. Also werde ich eine Frage stellen: „Welche Früchte haben rote oder gelbe Farbnuancen? “ über rote und runde Früchte und werde fragen „Welche Früchte sind grün und rund?“ nicht rote und runde Früchte. Anhand dieser Fragen kann ich mit großer Genauigkeit sagen, welche Äpfel es sind. Diese Kaskade von Fragen ist das, was ein Entscheidungsbaum ist. Dies ist jedoch ein Entscheidungsbaum, der auf meiner Intuition basiert. Intuition kann nicht mit hochdimensionalen und komplexen Daten funktionieren. Wir müssen uns die Kaskade von Fragen automatisch ausdenken, indem wir uns markierte Daten ansehen. Genau das tun Entscheidungsbäume, die auf maschinellem Lernen basieren. Frühere Versionen wie CART-Bäume wurden früher für einfache Daten verwendet, aber bei immer größeren Datensätzen muss der Kompromiss zwischen Verzerrung und Varianz mit besseren Algorithmen gelöst werden. Die beiden heute gebräuchlichen Algorithmen für Entscheidungsbäume sind Random Forests (die verschiedene Klassifikatoren auf einer zufälligen Teilmenge von Attributen aufbauen und sie für die Ausgabe kombinieren) und Boosting Trees (die eine Kaskade von Bäumen übereinander trainieren und die Fehler der Bäume unter ihnen korrigieren).
Entscheidungsbäume können zur Klassifizierung von Datenpunkten (und sogar zur Regression) verwendet werden
Bibliotheken
sklearn.ensemble.randomForestClassifier
sklearn.ensemble.gradientBoosting-Klassifikator
Einführendes Tutorial:
Random Forests verstehen: Von der Theorie zur Praxis
TD-Algorithmen (Gut zu haben)
Wenn Sie sich immer noch fragen, wie eine der oben genannten Methoden Aufgaben wie den Sieg über den Go-Weltmeister wie DeepMind lösen kann, können sie dies nicht tun. Bei allen 10 Arten von Algorithmen, über die wir zuvor gesprochen haben, ging es um Mustererkennung, nicht um Strategielerner. Um Strategien zur Lösung eines aus mehreren Schritten bestehenden Problems wie dem Gewinn einer Partie Schach oder dem Spielen auf der Atari-Konsole zu erlernen, müssen wir einen Agenten frei lassen und aus den Belohnungen/Strafen lernen, denen er ausgesetzt ist. Diese Art des maschinellen Lernens wird Reinforcement Learning genannt. Viele (nicht alle) der jüngsten Erfolge auf diesem Gebiet sind das Ergebnis der Kombination der Wahrnehmungsfähigkeiten eines Convnet oder LSTM mit einer Reihe von Algorithmen, die als Temporal Difference Learning bezeichnet werden. Dazu gehören Q-Learning, SARSA und einige andere Varianten. Diese Algorithmen sind ein cleveres Spiel mit den Bellman-Gleichungen, um eine Verlustfunktion zu erhalten, die mit Belohnungen trainiert werden kann, die ein Agent aus der Umgebung erhält.
Diese Algorithmen werden hauptsächlich zum automatischen Spielen von Spielen verwendet:D, auch für andere Anwendungen zur Sprachgenerierung und Objekterkennung.
Bibliotheken:
Deep Reinforcement Learning für Keras
Eine Open-Source-Implementierung des AlphagoZero-Algorithmus
Einführendes Tutorial (s):
Sehen Sie sich den David Silver-Kurs auf RL an
Dies sind die 10 Algorithmen für maschinelles Lernen, die Sie lernen können, um Datenwissenschaftler zu werden.
Wir hoffen, dir hat der Artikel gefallen. Bitte Melde dich an für ein kostenloses Komprehend-Konto, um Ihre KI-Reise zu beginnen. Sie können sich auch Demos der Komprehend KI-APIs ansehen hier.


.png)