Share it with your network.
In einem unserer vorherigen Beiträge haben wir zehn Algorithmen für maschinelles Lernen besprochen, die jeder Datenwissenschaftler kennen muss, um erfolgreich zu sein. Die Stimmungsanalyse fällt unter das Dach von Natural Language Processing. Klicken Sie hier, um mehr über die besten und kostenlosen Ressourcen für den Einstieg in NLP zu erfahren. Die Stimmungsanalyse ist wie ein Tor zur KI-basierten Textanalyse. Für jedes Unternehmen oder jeden Datenwissenschaftler, der Bedeutung aus einem unstrukturierten Textkorpus extrahieren möchte, ist die Stimmungsanalyse einer der ersten Schritte, der mit einem relativ geringen Zeit- und Arbeitsaufwand einen hohen ROI an zusätzlichen Erkenntnissen bietet. Angesichts der explosionsartigen Zunahme von Textdaten, die in digitalen Formaten verfügbar sind, wächst der Bedarf an Stimmungsanalysen und anderen NLU-Techniken zur Analyse dieser Daten rasant. Die Stimmungsanalyse sieht relativ einfach aus und funktioniert heute sehr gut, aber wir haben sie nach erheblichen Anstrengungen von Forschern erreicht, die verschiedene Ansätze erfunden und zahlreiche Modelle ausprobiert haben.
In der obigen Tabelle geben wir dem Leser einen Überblick über die verschiedenen erprobten Ansätze und ihre entsprechende Genauigkeit auf der IMDB-Datensatz. Wir weisen jedoch darauf hin, dass der IMDB-Datensatz relativ klein ist, weshalb andere Methoden im Vergleich zu neuronalen Netzwerken wettbewerbsfähig erscheinen. Wenn Sie diese Analyse an einem größeren Datensatz durchführen (wie dem Yelp-Datensatz mit 5 Leistungsklassen und über 4 Millionen Bewertungen) ändern sich die Rankings. Very Deep CNNs liefern beispielsweise eine Genauigkeit von bis zu 64,1% im Yelp-Datensatz, verglichen mit 63% bei FastText.
Wenn wir heute Stimmungsanalysen studieren, haben wir den Vorteil, auf den Schultern von Giganten zu stehen. Mit diesem Blogbeitrag geben wir unseren Senf dazu, indem wir den Lesern einen Überblick darüber geben, wie diese Technik der Textklassifizierung unter der Haube funktioniert. Wenn Sie das Gefühl haben, etwas verpasst zu haben, werden wir unseren Kreuze kriechen und die Liste bearbeiten, um sie vollständiger zu machen. Lesen Sie weiter und teilen Sie uns Ihre Gedanken in den Kommentaren mit.
RNN-basierte Modelle
Rekurrent Neural Networks wurden in den 1980er Jahren entwickelt. Viele Algorithmen, die wir in diesem Artikel besprechen werden, basieren auf RNNs. RNNs wenden rekursiv dieselbe Funktion (die Funktion, die sie während des Trainings lernt) auf eine Kombination aus vorherigem Speicher (als versteckte Einheit bezeichnet, die von Zeitpunkt 0 bis t-1 gesammelt wurde) und neuen Eingaben (zum Zeitpunkt t) an, um zum Zeitpunkt t ausgegeben zu werden. Allgemeine RNNs haben Probleme wie Gradienten, die aufgrund der rekursiven Natur zu groß und zu klein werden, wenn Sie versuchen, ein Stimmungsmodell mit ihnen zu trainieren.
[caption id="attachment_2154" align="alignnone“ width="962"]
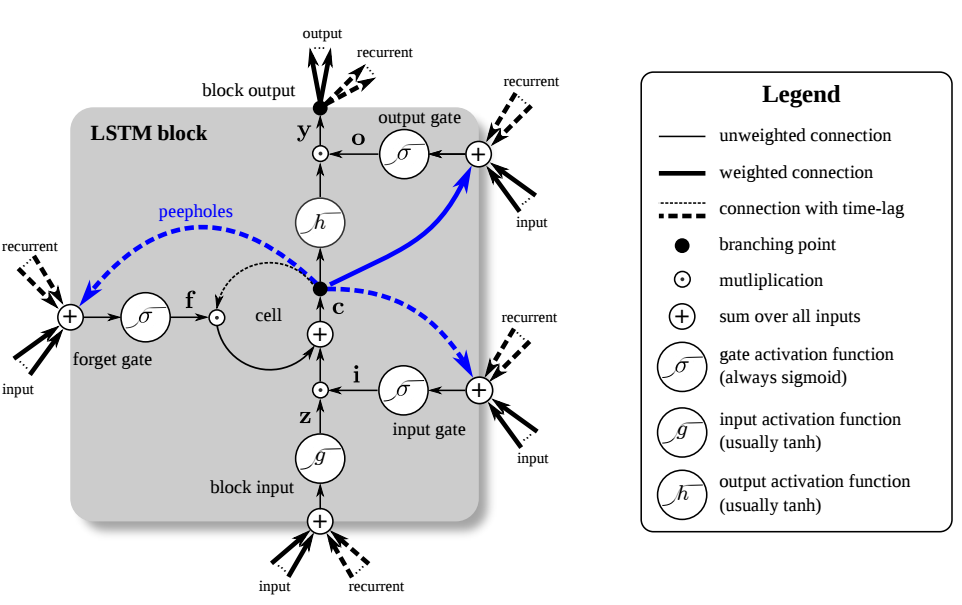
Ein LSTM-Block. Credits: Nvidia[/caption]
Langes Kurzzeitgedächtnis (LSTM) ist ein gradientenbasierter Lernalgorithmus, der lernen kann, Zeitintervalle auch bei lauten, inkompressiblen Eingabesequenzen zu überbrücken, ohne dass dabei die Fähigkeit zur kurzen Zeitverzögerung verloren geht. Dies wird durch einen gradientenbasierten Algorithmus erreicht, der einen konstanten Fehlerfluss in den internen Zuständen spezieller LSTM-Einheiten erzwingt. Der Algorithmus wurde 1997 von Sepp Hochrieter et al. vorgestellt. Im Wesentlichen wird die rekursive Anwendung von Funktionen in RNN gesteuert, indem sie in einen Additionsprozess umgewandelt wird.
Wiederkehrendes neuronales Netzwerk mit geschlossener Rückkopplung erweitert den bestehenden Ansatz, mehrere wiederkehrende Schichten zu stapeln, indem Signale, die von oberen rekurrenten Schichten zu unteren Schichten fließen, zugelassen und gesteuert werden, wobei für jedes Schichtpaar eine globale Gate-Einheit verwendet wird. Die zwischen den Schichten ausgetauschten wiederkehrenden Signale werden adaptiv auf der Grundlage der zuvor verborgenen Zustände und des aktuellen Eingangs gesteuert.
Sowohl LSTM als auch GF-RNN wurden nicht speziell mit dem Schwerpunkt Stimmungsanalyse geschrieben, aber viele Stimmungsanalysemodelle basieren auf diesen beiden häufig zitierten Artikeln.
Rekursives neuronales Tensornetzwerk
RNTN wurde 2011-2012 von Richard Socher et al. von Standfords NLP-Gruppe eingeführt. Die Autoren stellten das Recursive Neural Tensor Network vor, das auf einer anderen Art von Datensatz trainiert wurde, dem sogenannten Standford Sentiment Treebank. Das Stanford Sentiment Treebank war der erste Datensatz mit vollständig beschrifteten Parsebäumen, der eine vollständige Analyse der kompositorischen Auswirkungen von Stimmungen ermöglicht und es ermöglicht, die Feinheiten von Stimmungen zu analysieren und komplexe sprachliche Phänomene zu erfassen.
[caption id="attachment_2148" align="alignnone“ width="460"]
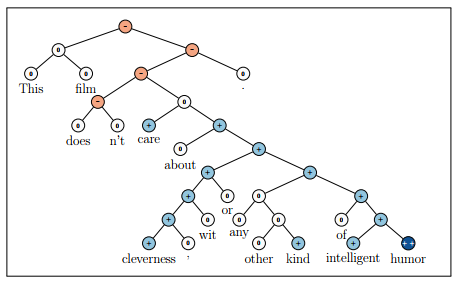
Beispiel für das rekursive neuronale Tensor-Netzwerk, das 5 Stimmungsklassen, sehr negativ bis sehr positiv (— —, 0, +, + +), an jedem Knoten eines Analysebaums genau vorhersagt.[/caption]
Das Modell übertraf alle bisherigen Methoden in Bezug auf mehrere Metriken und erhöhte den Stand der Technik bei der Positiv/Negativ-Klassifikation in einzelnen Sätzen von 80% auf 85,4%. Eine fortgeschrittenere Version dieses Algorithmus heißt Baum LSTM wurde 2015 von Christopher Manning et al. vorgeschlagen. Das Tree-LSTM-Modell ist eine Verallgemeinerung von LSTMs auf baumstrukturierte Netzwerktopologien. TreelSTMS übertreffen alle vorhandenen Systeme und starken LSTM-Basislinien bei der Stimmungsklassifizierung im Stanford Sentiment Treebank-Datensatz.
Aufmerksamkeitsbasierte neuronale Netze
Achtung als Konzept hat es viel Erfolg bei Sequenzmodellierungsaufgaben gebracht, bei denen sowohl Eingabe als auch Ausgabe eine Sequenz sind (wie bei der Übersetzung). Der Aufmerksamkeitsmechanismus kann als eine Methode angesehen werden, mit der das RNN besser funktioniert, indem das Netzwerk bei der Ausführung seiner Aufgabe darüber informiert wird, wo es suchen muss. Lange Zeit waren aufmerksamkeitsbasierte Modelle nicht für die Stimmungsanalyse und verwandte Aufgaben geeignet, bei denen das Ergebnis ein Attribut (+/-/neutral) für den gesamten Satz ist.
Die Erfindung von Selbstaufmerksamkeit hat in bestimmten NLP-Aufgaben, wie der Zusammenfassung und vielen anderen Bereichen, die sogar als unlösbar erachtet wurden, hervorragende Leistungen erbracht.
Dieses Papier von Zhouhan Lin et al. schlugen ein neues Modell zur Extraktion einer interpretierbaren Satzeinbettung vor, indem Selbstaufmerksamkeit eingeführt wird. Anstatt einen Vektor zu verwenden, verwendeten die Autoren eine 2D-Matrix, um die Einbettung darzustellen, wobei sich jede Zeile der Matrix auf einen anderen Teil des Satzes bezog. Bei der Selbstaufmerksamkeit handelt es sich um gewichtete Informationen, die entsprechend der globalen Bedeutung über verschiedene Teile eines Satzes verteilt werden.
[caption id="attachment_2149" align="alignnone“ width="307"]
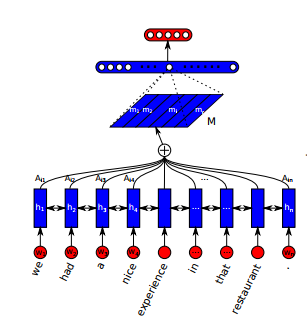
Eine Beispielmodellstruktur, die das Satzeinbettungsmodell in Kombination mit einer vollständig verbundenen Softmax-Ebene für die Stimmungsanalyse zeigt[/caption]
Das vorgeschlagene Satzeinbettungsmodell besteht aus zwei Teilen. Der erste Teil ist ein bidirektionales LSTM, und der zweite Teil ist der Selbstaufmerksamkeitsmechanismus, der eine Reihe von Summengewichtungsvektoren für die versteckten LSTM-Zustände bereitstellt. Diese Gruppe von Vektoren für die Summengewichtung ist mit den versteckten LSTM-Zuständen übersät, und die daraus resultierenden gewichteten versteckten LSTM-Zustände werden als Einbettung für den Satz betrachtet.
Aufmerksamkeit ist alles was du brauchst, ein im Juni 2017 von Ashish Vaswani et al. veröffentlichter Artikel, präsentierte die Transformator, das erste Sequenztransduktionsmodell, das ausschließlich auf Aufmerksamkeit basiert und die in Encoder-Decoder-Architekturen am häufigsten verwendeten rekurrenten Schichten durch mehrköpfige Selbstaufmerksamkeit ersetzt. Netzwerke, die nur auf Aufmerksamkeit basieren, könnten RNN-basierte Netzwerke (RNTN/RNN/LSTM/GRU) für einige NLP-Aufgaben (z. B. eine Übersetzung) komplett fertigstellen, aber wir müssen noch überzeugende Argumente für eine Stimmungsanalyse mit diesen Modellen vorlegen.
Auf Multitask-Lernen basierende Modelle
Eine andere Methode, die großen Erfolg haben kann, ist Multitask-Lernen (MTL). MTL ist ein Teilbereich des maschinellen Lernens, in dem mehrere Lernaufgaben gleichzeitig gelöst werden und gleichzeitig Gemeinsamkeiten und Unterschiede zwischen den Aufgaben ausgenutzt werden. Dies kann im Vergleich zum separaten Training der Modelle zu einer verbesserten Lerneffizienz und Prognosegenauigkeit für die aufgabenspezifischen Modelle führen.
[caption id="attachment_2152" align="alignnone“ width="475"]
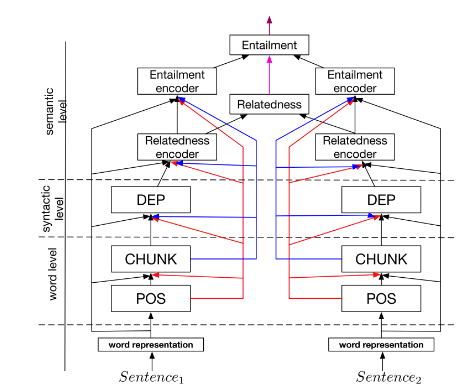
Ein gemeinsames Viel-Task-Modell (Hashimoto et al., 2016)[/caption]
Bei Parallele Punkte, wir haben einen MTL-Datensatz, der von unserem eigenen Tagging-Team markiert wurde, und unser neues Stimmungsmodell (das bald auf den Markt kommt) ist ein MTL-Modell mit Self Attention.
Faltungsneuronale Netze
Klöster kann auch für Stimmungsvorhersagen verwendet werden. Yoon Kim schlug eine vor Architektur des Klosters zur Satzklassifizierung. Kim berichtete über eine Reihe von Experimenten mit neuronalen Faltungsnetzwerken (CNN), die auf vortrainierten Wortvektoren für Klassifikationsaufgaben auf Satzebene trainiert wurden, und zeigte, dass ein einfaches CNN mit wenig Hyperparameter-Abstimmung und statischen Vektoren bei mehreren Benchmarks hervorragende Ergebnisse erzielt. Das Erlernen aufgabenspezifischer Vektoren durch Feinabstimmung bietet weitere Leistungssteigerungen des Modells.
Bei ParallelDots hatten wir dies lange Zeit als Stimmungsmodell. Unser aktuelles Stimmungsmodell ist ein vielschichtiges LSTM. Wie bereits erwähnt, wechseln wir mit Selbstaufmerksamkeit zum MTL-Modell.
[caption id="attachment_2150" align="alignnone“ width="576"]
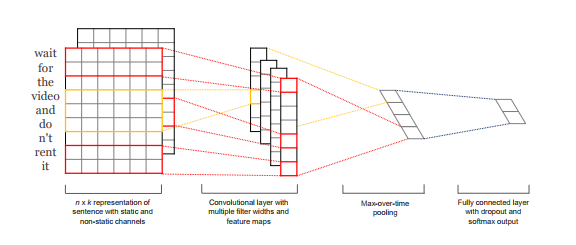
Kims Modellarchitektur mit zwei Kanälen für einen Beispielsatz[/caption]
Eine bessere Convnet-Version für die Stimmungsanalyse veröffentlichen Nal Kalchbrenner et al. in diesem Papier. Der Autor schlug eine vor Dynamisches neuronales Faltungsnetzwerk (DCNN) Architektur für Satzmodellierungsaufgaben.
Unbeaufsichtigtes Stimmungsneuron
Wenn Sie einen großen Korpus an Sätzen haben, die mit Emotionen/Polaritäten gefüllt sind, KI öffnen hat gezeigt, dass man den Korpus nicht einmal taggen muss, um ein überwachtes Sentiment zu trainieren. Sie haben gezeigt, dass ein normaler RNN auf Charakterebene die positive/negative Stimmung selbst herausfinden kann. Diese Studie unterstreicht die Bedeutung von Data Quantum für maschinelles Lernen.
[caption id="attachment_2151" align="alignnone“ width="745"]
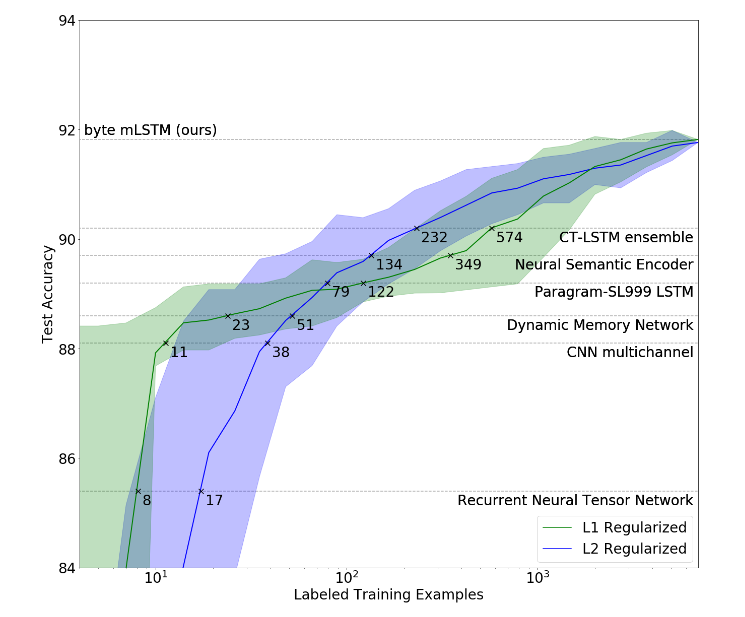
Das L1-regularisierte Modell (das in Amazon-Rezensionen unbeaufsichtigt vortrainiert wurde) entsprach der Mehrkanalleistung von CNN mit nur 11 markierten Exemplaren und hochmodernen CT-LSTM-Ensembles mit 232 Beispielen[/caption]
Öffnen Sie KIs Unbeaufsichtigtes Modell Durch die Verwendung dieser Darstellung wurde eine Genauigkeit der Stimmungsanalyse auf dem neuesten Stand der Technik bei einem kleinen, aber umfassend untersuchten Datensatz, der Stanford Sentiment Treebank, erreicht. Die Genauigkeit lag bei 91,8% gegenüber dem vorherigen Bestwert von 90,2%. Außerdem erreichte das Modell die Leistung früherer überwachter Systeme, wobei 30-100x weniger beschriftete Beispiele verwendet wurden. Die vom Modell erstellte Darstellung enthält eine eindeutige Gefühlsneuron das fast das gesamte Stimmungssignal enthält.
Auf nichtneuronalen Netzwerken basierende Modelle
Einige Modelle, die auf nichtneuronalen Netzwerken basieren, haben eine signifikante Genauigkeit bei der Analyse der Stimmung eines Korpus erreicht.
Naive Bayes - Unterstützung von Vektormaschinen (NBSVM) funktioniert sehr gut, wenn der Datensatz sehr klein ist, manchmal funktionierte er besser als die auf neuronalen Netzwerken basierenden Modelle. Sida Wang et al. zeigten, dass die einfachen NB- und SVM-Varianten die meisten veröffentlichten Ergebnisse bei mehreren Datensätzen zur Stimmungsanalyse (Schnipsel und längere Dokumente) übertrafen und manchmal ein neues Leistungsniveau auf dem neuesten Stand der Technik darstellten.
Schneller Text ist ein Supervised Word2Vec-Modell. Es ist vielleicht nicht das beste, was die Genauigkeit angeht, aber es untersucht eine einfache und effiziente Grundlage für die Textklassifizierung. FastText lässt sich um viele Größenordnungen schneller trainieren und evaluieren als die auf Deep Learning basierenden Modelle. Es kann mit einer Standard-Mehrkern-CPU in weniger als zehn Minuten an mehr als einer Milliarde Wörtern trainiert werden und klassifiziert in weniger als einer Minute eine halbe Million Sätze aus 312.000 Klassen. Es kann auch zur Stimmungsklassifizierung verwendet werden.
Tiefer Wald kam Anfang 2017 heraus und behauptete, mit Decision Tree-ähnlichen Methoden auf dem neuesten Stand der Technik bei der Stimmungsanalyse zu sein, sogar besser als jedes Modell, das auf neuronalen Netzwerken basiert. Zhi-Hua Zhou et al. schlugen dieses Modell vor, auch bekannt als GC-Wald (Multigrained Cascade Forest), eine Baumensemble-Methode. Diese Methode generiert ein Deep-Forest-Ensemble mit einer Kaskadenstruktur, die es GcForest ermöglicht, Repräsentationslernen durchzuführen. DeepForest erweiterte den Stand der Technik für Stimmungsanalysen auf IMDB-Datensatz indem Sie eine Testgenauigkeit von 89,16% erreichen.
[caption id="attachment_2153" align="alignnone“ width="718"]
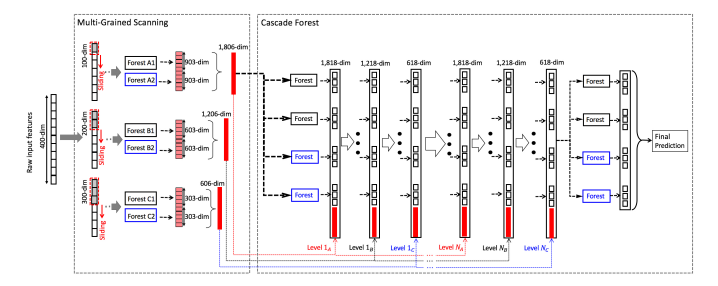
Das gesamte Verfahren von GcForest[Bildunterschrift]
Lange Zeit wurde diese Methode in der realen Welt nicht repliziert, aber jetzt sind die Wege frei, damit sie sich auf die Reise begeben kann. Du kannst folgen diese Diskussion auf der Github-Seite von Microsoft LightGBM für weitere Informationen zu DeepForest. Für Modelle, die nicht auf neuronalen Netzwerken basieren, scheint DeepForest die beste Wahl zu sein.
Angesichts umfangreicher Forschungsarbeiten sowohl an neuronalen Netzwerken als auch an Modellen, die nicht auf neuronalen Netzwerken basieren, wird sich die Genauigkeit von Stimmungsanalysen und Klassifikationsaufgaben voraussichtlich verbessern. Früher bestand eine große Herausforderung im Zusammenhang mit Deep-Learning-Modellen darin, dass die neuronalen Netzwerkarchitekturen hochgradig auf bestimmte Anwendungsbereiche spezialisiert waren. Selbst die Lösung eines sehr ähnlichen Problems erforderte ein erneutes Training und eine Neubewertung des Modells. Mit dem Aufkommen des Multitask-Lernens stellen wir uns Modelle vor, die mehrere verwandte Aufgaben gleichzeitig ausführen können. Diese Fortschritte bei der Entwicklung eines vielseitigen Modells zur Ausführung ähnlicher Aufgaben scheinen ein Weg der Zukunft zu sein.
Wir hoffen, dir hat der Artikel gefallen. Bitte Melde dich an für ein kostenloses Komprehend-Konto, um Ihre KI-Reise zu beginnen. Sie können sich auch Demos der Komprehend KI-APIs ansehen hier. Melde dich an heute und erhalte die ersten 4000 Credits absolut kostenlos.


.png)